Donnerstag, 15. Oktober 2015
Donnerstag, 11. Oktober 2012
Bachelor Thesis - Vorstellung meiner Abschlussarbeit

Meine Arbeit trägt den Titel „Visual-aided selection of
reactive elements in intelligent environments“ (Visuell gestützte Selektion
reaktiver Elemente in intelligenten Umgebungen) und behandelt die Problematiken
bei der Interaktion zwischen Menschen und Computern mittels
Gestensteuerung.
Die Problemstellung und die damit verbundene Aufgabenstellung wandelten sich während der Bearbeitungsphase. In der ursprünglichen Aufgabenstellung sollte ich untersuchen, welche Art von Rückmeldung der
Mensch benötigt, um in einer intelligenten Umgebung mit
reaktiven Elementen mittels Gesten zu interagieren.
Normalerweise ist das Verständnis einer Interaktion mit einem Computer folgende: Man hat ein Eingabegerät und ein Ausgabegerät – alles was man mit dem Eingabegerät anstellt hat eine mehr oder minder direkte Auswirkung auf das Ausgabegerät. Beim handelsüblichen Computer wäre das Eingabegerät z.B. die Maus, das Ausgabegerät der z.B. Monitor. Wähle ich nun ein Programmsymbol mittels der Maus aus, so sehe ich auf dem Bildschirm irgendeine optische Reaktion auf meine Tat - z.B. blinkt und springt das Symbol. Klicke ich auf das Symbol, passiert eine weitere Reaktion, welche ich auf dem Monitor angezeigt bekomme - z.B. ein Programm wird gestartet und angezeigt. In der heutigen Zeit verlagern sich Computersysteme jedoch immer mehr vom ursprünglich festen Arbeitsplatz, wie dem Schreibtisch, in alle Bereiche unserer Umgebung; sie werden Mobil wie z.B. durch das Smartphone oder ein Tablet-PC, oder integrieren sich sogar in Haushaltsgegenstände wie z.B. Kühlschränke, Fernseher oder gar Möbel. Während nun ein solches mobiles Gerät - beispielsweise ein Smartphone - weiterhin einen Bildschirm enthält und die Interaktion direkt über den Touchscreen erfolgt, muss dies nicht für einen Kühlschrank, oder ein Sofa gelten.
Normalerweise ist das Verständnis einer Interaktion mit einem Computer folgende: Man hat ein Eingabegerät und ein Ausgabegerät – alles was man mit dem Eingabegerät anstellt hat eine mehr oder minder direkte Auswirkung auf das Ausgabegerät. Beim handelsüblichen Computer wäre das Eingabegerät z.B. die Maus, das Ausgabegerät der z.B. Monitor. Wähle ich nun ein Programmsymbol mittels der Maus aus, so sehe ich auf dem Bildschirm irgendeine optische Reaktion auf meine Tat - z.B. blinkt und springt das Symbol. Klicke ich auf das Symbol, passiert eine weitere Reaktion, welche ich auf dem Monitor angezeigt bekomme - z.B. ein Programm wird gestartet und angezeigt. In der heutigen Zeit verlagern sich Computersysteme jedoch immer mehr vom ursprünglich festen Arbeitsplatz, wie dem Schreibtisch, in alle Bereiche unserer Umgebung; sie werden Mobil wie z.B. durch das Smartphone oder ein Tablet-PC, oder integrieren sich sogar in Haushaltsgegenstände wie z.B. Kühlschränke, Fernseher oder gar Möbel. Während nun ein solches mobiles Gerät - beispielsweise ein Smartphone - weiterhin einen Bildschirm enthält und die Interaktion direkt über den Touchscreen erfolgt, muss dies nicht für einen Kühlschrank, oder ein Sofa gelten.
 |
| Auf der Cyberworld 2012 vorgestelltes Paper |
Noch gravierender wird es, wenn die einzelnen Geräte miteinander kommunizieren und Daten untereinander austauschen. So ist es bereits heute im Living Lab - einer intelligenten Wohnumgebung die als Test- und Demobereich für Ambient Intelligence Forschung am Fraunhofer IGD dient - möglich durch das Einnehmen bestimmter Sitzpositionen auf dem Sofa die Lichtstimmung im Raum zu verändern. Dieses Beispiel einer indirekten Steuerung zeigt, dass es nicht immer offensichtlich sein muss, welche Reaktion auf eine Aktion folgt. Eine nicht instruierte Person kann die Möglichkeit der Veränderung der Lichtstimmung erst durch das erstmalige Hinsetzen bemerken. Welche Lichtstimmungen möglich sind, muss sie durchs Probieren herausfinden.
Um dem zumindest im Bereich der Gestensteuerung entgegenzuwirken sollte ich nicht nur das Problemfeld
näher betrachten, sondern meine Erkenntnisse zur Verbesserung der
Situation auch durch eine funktionale Umsetzung demonstrieren.
Dank der Markteinführung von Microsofts Kinect und der aktiven Gemeinschaft unabhängiger Entwickler, stand eine sehr preisgünstige und für meine Zwecke ideale Technologie zum Erkennen und Verarbeiten von Gesten bereit. Die Tiefenkamera von Microsoft erkennt die Silhouetten davorstehender Personen und berechnet aus diesen ein vereinfachtes Skelettmodell mit allen benötigten dreidimensionalen Werten. So kann man z.B. die Zeigerichtung im Raum erkennen und für die Interaktion nutzen.
Dank der Markteinführung von Microsofts Kinect und der aktiven Gemeinschaft unabhängiger Entwickler, stand eine sehr preisgünstige und für meine Zwecke ideale Technologie zum Erkennen und Verarbeiten von Gesten bereit. Die Tiefenkamera von Microsoft erkennt die Silhouetten davorstehender Personen und berechnet aus diesen ein vereinfachtes Skelettmodell mit allen benötigten dreidimensionalen Werten. So kann man z.B. die Zeigerichtung im Raum erkennen und für die Interaktion nutzen.

 Die Art der Eingabe abseits von Maus und Tastatur war also
vorhanden, doch wie sollte die Ausgabe aussehen, so dass kein stationärer, oder
mobiler Bildschirm benötigt wurde? Die Nutzung eines solchen stationären Ausgabegerätes hätte zwei gravierende Nachteile, die ich in meiner Arbeit aufzeigen und vermeiden wollte. Zum Einen müsste ein mobiler
Bildschirm immer in irgend einer Art und Weise mitgeführt werden, was wiederum der „Unaufdringlichkeit“
einer intelligenten Umgebung entgegenwirken würde, zum Anderen könnte ein stationärer
Bildschirm, wie z.B. der Fernseher im Wohnzimmer, nicht überall für die
benötigte Rückmeldung genutzt werden, weil er z.B. nicht im Blickfeld steht. Auch andere Ausgabevarianten, wie akustische Meldungen, oder Vibrationsmotoren
in der Kleidung - um nur zwei zu nennen – schieden aus. Diese würden entweder
aufdringlich in den Wahrnehmungsbereich einer zweiten Person, welche mit der Interaktion
nichts zu tun hat, dringen, oder
müssten wiederum ständig mitgeführt werden.
Die Art der Eingabe abseits von Maus und Tastatur war also
vorhanden, doch wie sollte die Ausgabe aussehen, so dass kein stationärer, oder
mobiler Bildschirm benötigt wurde? Die Nutzung eines solchen stationären Ausgabegerätes hätte zwei gravierende Nachteile, die ich in meiner Arbeit aufzeigen und vermeiden wollte. Zum Einen müsste ein mobiler
Bildschirm immer in irgend einer Art und Weise mitgeführt werden, was wiederum der „Unaufdringlichkeit“
einer intelligenten Umgebung entgegenwirken würde, zum Anderen könnte ein stationärer
Bildschirm, wie z.B. der Fernseher im Wohnzimmer, nicht überall für die
benötigte Rückmeldung genutzt werden, weil er z.B. nicht im Blickfeld steht. Auch andere Ausgabevarianten, wie akustische Meldungen, oder Vibrationsmotoren
in der Kleidung - um nur zwei zu nennen – schieden aus. Diese würden entweder
aufdringlich in den Wahrnehmungsbereich einer zweiten Person, welche mit der Interaktion
nichts zu tun hat, dringen, oder
müssten wiederum ständig mitgeführt werden.
Das Rückmeldesystem sollte somit vor Ort aber nicht
stationär, mobil aber nicht am Körper des Benutzers und überall im Raum
verfügbar, aber nicht aufdringlich und störend sein. Die Lösung, welche mir am
geeignetsten erschien, war also eine optische Darstellung der Ausgabe mittels
Projektion. Im Rahmen der Bachelorarbeit baute ich einen
kleinen Laserprojektor, der mittels Modellbau-Motoren ausgerichtet und durch
einen Arduino Mikrocontroller und einem umfangreichen Softwarepaket gesteuert
wurde. Das projizierte Licht lieferte eine kleine LED Laserdiode.
Als Resultat entstand das Environmental Aware Gesture Leading Equipment (E.A.G.L.E.) System.

Den Projektionsroboter taufte ich E.A.G.L.E. Eye.
Die Implementierung des gesamten Systems erforderte einen erheblichen Teil meiner dreimonatigen Thesis-Zeit, viele graue Haare, noch mehr schlaflose Nächte und einen nicht unbedeutenden Anteil meines Nervenkostüms, doch das Resultat sollte sich auszahlen.
Bezüglich der detaillierten Implementierung der Hardware und Software werde ich mich an dieser Stelle kurz fassen.
Einige interessante Aspekte der Umsetzung bieten aber Stoff für weitere Artikel auf meinem Blog und sollen dann auch den dafür nötigen Rahmen erhalten.
Bezüglich der detaillierten Implementierung der Hardware und Software werde ich mich an dieser Stelle kurz fassen.
Einige interessante Aspekte der Umsetzung bieten aber Stoff für weitere Artikel auf meinem Blog und sollen dann auch den dafür nötigen Rahmen erhalten.
Um ein Verständnis der technischen Umsetzung zu erhalten kann man die Funktionsweise des E.A.G.L.E. Systems in folgenden Punkten beschreiben:
- Die Kinect erkennt den Benutzer und erstellt eine virtuelle Skelettdarstellung
- Das Skelett wird dazu benutzt die Zeige und Auswahlgesten zu erkennen.
- Diese Gesten werden mit einer virtuellen Repräsentation des Raums und seiner Geräte in Relation gesetzt.
- Die erkannte Zeigegeste in diesem virtuellen Raum bzw. die Auswahl eines Gerätes in diesem wird als Befehlssatz an das E.A.G.L.E. Eye gesendet.
- Das E.A.G.L.E. Eye richtet den Laserpunkt auf die Position im reellen Raum aus.

 |
| E.A.G.L.E. Eye |
- Dauerhaftes Leuchten beim Zeigen in den Raum
- Blinken beim Zeigen auf ein reaktives Gerät
- Schnelles Blinken bei erfolgter Auswahl des Gerätes [2]
Wie ich oben bereits erwähnt habe, war die ursprüngliche
Idee der Bachelor Thesis die Herausarbeitung verschiedener Feedback-Varianten.
Angedacht war zu untersuchen ob
komplexere Menüstrukturen nötig sind und in wieweit diese die gestenbasierte Interaktion mit einem Gerät beeinflussen. Des Weiteren sollte herausgefunden werden, wie komplex eine solche Menüstruktur mindestens sein muss, oder höchstens sein darf, damit sie
trotz Gestensteuerung noch gut bedienbar bleibt.
Der Schwerpunkt änderte sich jedoch immer mehr, je weiter
die Entwicklung am E.A.G.L.E. System voranschritt. Gleich nach den ersten
Testläufen durch meine beiden Betreuer Andreas Braun, Alexander Marinc und mir selbst stellte sich eine ganz andere Frage:
Mit welchem Teil meines Arms zeige ich wohin in den Raum?
Diese Frage mag verwundern, zeigen wir Menschen doch Tag
ein, Tag aus irgendwo hin und irgendwo drauf und werden zumeist ohne weiteres von unseren Mitmenschen verstanden - falls nicht, erklären wir unsere Intention auf einem anderen Wege wie z.B. verbal.
So bedeutungslos die Frage somit auch klingen mag, so tiefgehend beeinflusste sie die Testläufe: Drei Personen testeten den E.A.G.L.E Prototypen, drei Personen waren komplett unterschiedlicher Meinungen darüber mit welchen Teilen ihres Oberkörpers sie auf welchen Punkt im Raum zeigten.
Diese Diskrepanz wird dadurch ausgelöst, dass auf der anderen Seite der Interaktionskette kein Mensch sondern ein Computersystem sitzt. Bereits die wichtigste Komponente dieser Kette macht einer intuitiven Interaktion einen Strich durch die Rechnung: Die Kinect! Dieses für die Thesis interessante, weil kostengünstige und gut programmierbare Gerät liefert ein sehr einfaches Skeletmodel aus den Bilddaten, über welches man die Zeigegesten interpretieren muss. Zur Anschauung dient folgende Abbildung und die drei möglichen Wege eine einfache Zeigerichtung zu bestimmen:
So bedeutungslos die Frage somit auch klingen mag, so tiefgehend beeinflusste sie die Testläufe: Drei Personen testeten den E.A.G.L.E Prototypen, drei Personen waren komplett unterschiedlicher Meinungen darüber mit welchen Teilen ihres Oberkörpers sie auf welchen Punkt im Raum zeigten.
Diese Diskrepanz wird dadurch ausgelöst, dass auf der anderen Seite der Interaktionskette kein Mensch sondern ein Computersystem sitzt. Bereits die wichtigste Komponente dieser Kette macht einer intuitiven Interaktion einen Strich durch die Rechnung: Die Kinect! Dieses für die Thesis interessante, weil kostengünstige und gut programmierbare Gerät liefert ein sehr einfaches Skeletmodel aus den Bilddaten, über welches man die Zeigegesten interpretieren muss. Zur Anschauung dient folgende Abbildung und die drei möglichen Wege eine einfache Zeigerichtung zu bestimmen:

- Als Linie zwischen Kopf und Handgelenk
- Als Linie zwischen Schultergelenk und Handgelenk
- Als Linie zwischen Ellbogen und Handgelenk
Und ausgerechnet die dem Menschen am meisten bevorzugte Variante, das Zeigen über die Gelenke des Zeigefinders, kann nicht genutzt werden. Zur Darstellung der Finger ist die Kinect (der ersten Generation) nicht technisch in der Lage - es wäre unter bestimmten Vorraussetzungen möglich, aber für mein Aufgabenfeld nicht umsetzbar.
Doch auch wenn die Technik diese Beschränkung nicht inne hätte, wäre die Problematik längst nicht vom Tisch. So hat sich schnell herausgestellt, dass der eine Proband immer über die Augen zur Spitze seines Zeigefingers zeigt, während ein anderer Proband gerne den Unterarm als Verlängerung seines "Zeigegerätes" benutzt. Viel gravierender als diese benutzerspezifische Vorliebe beim Zeigen ist der Unterschied zwischen der gedachten und der vom System erkannten Zeigerichtung und dem daraus resultierenden Zeigeziel. Während der Mensch der Meinung ist seinen Körper und seine Hand-Augen-Koordination perfekt zu beherrschen, entlarvt das Computersystem jedes Zittern und jeden Drift - z.B. durch Ermüdung der Muskeln. Diese Veränderungen mögen für den Menschen unmerklich groß sein, wirken sich aber numerisch bereits so gravierend aus, dass bereits auf wenigen Metern ein Versatz von mehreren Dezimetern entstehen kann. Anstelle somit auf den Fernseher zu zeigen, zeigt man auf die Blumenvase daneben und wundert sich, wieso der Fernseher nicht reagiert. Die technische Umsetzung der Kinect steuert zu dieser Variant sicherlich ihren Teil bei, doch auch eine präzisere Sensortechnik nicht zu 100% mit der Intention des Benutzers übereinstimmen.
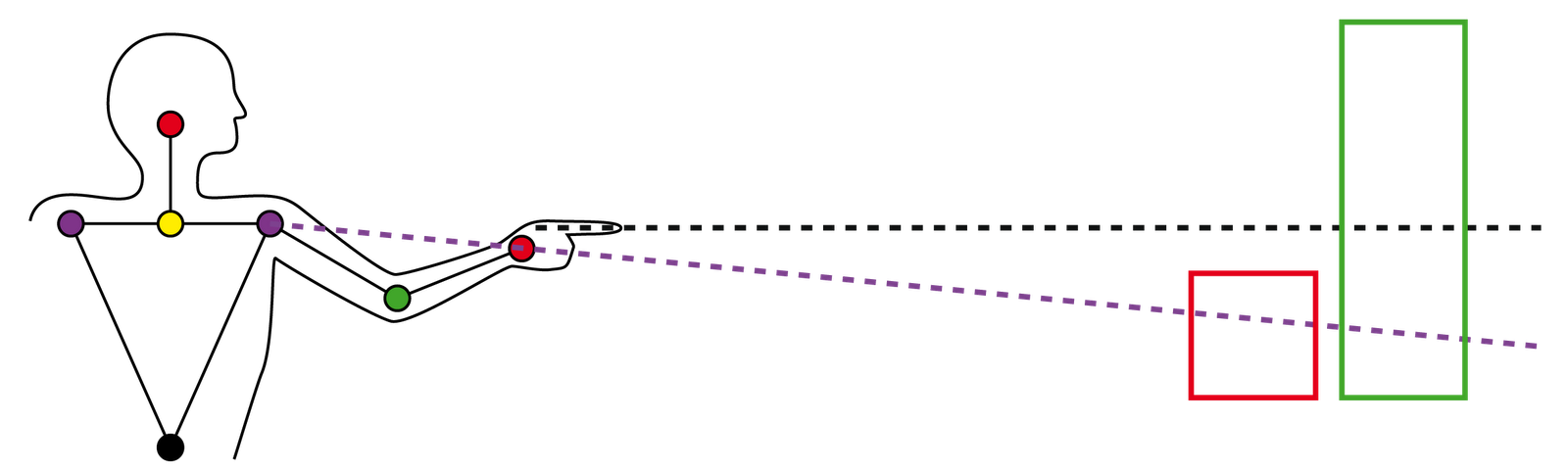 |
| Unterschied zwischen gedachter und erkannter Zeigerichtung. |
 |
| Bereits geringe Schwankungen führen zu erheblichem Richtungsversatz. |
Nutzt man nun ein klassisches System, wie den oben genannten
Desktop PC mit der Maus als Zeigegerät, so hat man mehrere begünstigende
Faktoren sein Ziel auch zu erreichen. Die Maus liegt recht stabil auf der
Unterlage. Lässt man sie los, so bleibt sie zumeist auch dort liegen. Bewegt man die
Maus, so bewegt man zwar faktisch seine Hand, folgt aber dem Mauszeiger auf dem
Bildschirm. Ohne diesen Zeiger und ohne eine stabile Ruheposition wäre es auch hier nicht möglich präzise mit dem PC zu interagieren.
Wenn aber der Mensch am PC in der Lage ist einem Mauszeiger
zu folgen, der räumlich so drastisch getrennt vom physikalischen Zeigegerät
ist, wieso sollte das nicht auch im reellen Raum mittels Zeigegesten funktionieren? Muss der Mensch
nicht einfach nur verstehen was der PC erkennt und interpretiert, um sich an diesen anzupassen?
Ist die Adressierung der Anpassung von Seiten des Menschen nicht deutlich einfacher, als wenn man
komplexe Algorithmen schreibt, welche man an den Menschen anpassen muss?
Diesen Fragen in Kombination mit der banal anmutenden Frage „Wo zeige ich
eigentlich hin?“ widmete ich von diesem Zeitpunkt an meine Bachelorarbeit. Nun
war es nicht mehr wichtig verschiedene Darstellungen zu erproben und zu schauen
wie komplex diese werden müssen, sondern einfach darum überhaut einen anständig
funktionierenden Navigations- und Auswahlprozess im intelligenten Raum mittels
Zeigegesten zu ermöglichen.
Das E.A.G.L.E. System wurde dahingehend erweitert, dass
genau dieser Prozess der Navigation und der Geräteauswahl anständig und in
annähernder Echtzeit funktioniert.
Meine Hypothese: Der Mensch ist ohne ein angemessenes
Rückmeldesystem nicht in der Lage eine durchgehend erfolgreiche Auswahlaktion
im Raum mittels Gesten durchzuführen, auch wenn man ihn detailliert über die
Berechnungsweise seiner Zeigegeste instruiert. Die Aussicht auf Erfolg dieses
Prozesses lässt sich durch ein geeignetes Rückmeldesystem signifikant
verbessern. Dazu ist es im letzteren Fall nicht einmal mehr nötig das System
durch komplexere Algorithmen intelligenter zu gestalten.
Zur Evaluation lud ich zwanzig Testkandidaten ein, welche
einen festgelegten Parcours bestehend aus acht Zielen verschiedener Größe,
Orientierung und Position im Raum mit einer Zeigegeste ansteuern und durch zwei
Sekunden langes Halten dieser Zeigegeste auswählen sollten. Zehn dieser Personen
mussten den Parcours erst ohne, dann mit der Unterstützung des Laserprojektors
durchführen, die anderen zehn Personen genau in umgekehrter Reihenfolge.
Neben dem Nachweis der Hypothese erhoffte ich mir zusätzlich,
dass die Nutzung des E.A.G.L.E. Systems einen gewissen Lerneffekt für den
Durchlauf ohne das System auf die Kandidaten haben würde.
 Die Hypothese konnte ich mit absoluter Zufriedenheit
beweisen. Alle Personen waren mit der Unterstützung des Lasers zu 100% in der
Lage die Zielscheiben anzuvisieren und auszuwählen. Auch wenn es manchmal nicht
auf den ersten Fingerzeig geklappt hat, so wussten die Kandidaten um ihren
Fehler und konnten diesen korrigieren. Ohne die unterstützende Projektion waren
erfolgreiche Auswahlaktionen hingegen ein Akt des Zufalls. Sogar die großen
Ziele mit 3060 Quadratzentimetern - die Größe eines DinA3 Blattes - wurden nur selten erfolgreich ausgewählt.
Die Hypothese konnte ich mit absoluter Zufriedenheit
beweisen. Alle Personen waren mit der Unterstützung des Lasers zu 100% in der
Lage die Zielscheiben anzuvisieren und auszuwählen. Auch wenn es manchmal nicht
auf den ersten Fingerzeig geklappt hat, so wussten die Kandidaten um ihren
Fehler und konnten diesen korrigieren. Ohne die unterstützende Projektion waren
erfolgreiche Auswahlaktionen hingegen ein Akt des Zufalls. Sogar die großen
Ziele mit 3060 Quadratzentimetern - die Größe eines DinA3 Blattes - wurden nur selten erfolgreich ausgewählt.
So signifikant wie dieses Ergebnis ausfiel, so wenig konnte
ich über einen Lerneffekt herausfinden. Die festgestellten Unterschiede waren
nicht aussagekräftig genug. Ein Fall für weitere Untersuchungsanstrengungen?!
Nichtsdestotrotz war ich sehr zufrieden mit dem Ausgang der
Evaluation. Die Bachelorarbeit
gefiel anscheinend ebenso meinem betreuenden Professor Arian Kuijper, sowie meinen beiden
Betreuern Andreas Braun und Alexander Marinc: Die Thesis wurde mit einer glatten 1.0 bewertet.
Wer sich detaillierter für meine Bachelor Thesis oder derer Präsentation interessiert, der kann sie sich unter folgendem Link herunterladen und
durchlesen.
Als positiver Nebeneffekt der erbrachten wissenschaftlichen
Erkenntnisse wurde meine Bachelorarbeit in einem Paper auf der
diesjährigen Cyberworld veröffentlicht und präsentiert.
Des Weiteren möchte ich mich bei meinem Kumpel (und Chef) Felix Kamieth bedanken, der mich während der Abschlussarbeit nur ganz gering mit Arbeit zugeschüttet und moralisch oft unterstützt hat.
[1] Diese
Verbreitung wird als allgegenwärtige (ubiquitous) und verschwindende (vanishing) bzw. unaufdringliche (unobtrusive) Computerisierung
bezeichnet. Ein Raum, in welchem die verschiedensten Geräte nicht nur für sich
computergestützt arbeiten, sondern auch miteinander kommunizieren und Daten
austauschen, um irgend eine komplexere Funktionalität auszuführen (z.B. eine
Reaktion auf das Wohlbefinden eines Bewohners), heißt intelligenter Wohnraum (intelligent environment).
[2] Ein Gerät wird ausgewählt, wenn der Benutzer durchgehend mindestens zwei Sekunden lang auf dieses gezeigt hat.
[2] Ein Gerät wird ausgewählt, wenn der Benutzer durchgehend mindestens zwei Sekunden lang auf dieses gezeigt hat.
Mittwoch, 20. Juni 2012
IGD / Studium - Android Home Control
Im Sommer 2011 entwickelte ich im Rahmen eines Studienpraktikums für ein Ambient Intelligence Project am Fraunhofer IGD eine graphische Software-Infrastruktur mit welcher man eine intelligente Wohnungumgebung bequem vom Sofa aus bedienen kann: Das Android Home Control (AHC).
Die Software besteht aus drei wesentlichen Komponenten:
Da es sich bei dem Projekt um ein Ein-Mann-Praktikum während des Sommersemester gehandelt hat, für welches ich ca. vier Monate Zeit hatte (neben anderen Vorlesungen und privaten Verpflichtungen), ist das AHC Projekt rein als Demonstrator bzw. "Proof of concept" umgesetzt worden und damit natürlich noch stark entwicklungsfähig. Stolz macht mich, dass die gesamte Android Home Control Infrastruktur sehr robust und zuverlässig arbeitet, so dass sie bereits für weitere Praktikas anderer Studenten genutzt wurde und in meinen Notenspiegel mit einer 1.0 als Note einfloss.
Der Fokus lag auf der Entwicklung einer grundlegenden Plattform zur direkten Steuerung einer Wohnumgebung von einem Tablet aus. In die Entwicklung flossen die folgenden Schritte ein:
Die Android Home Control App konnte auch auf der CeBit 2012 am Fraunhofer IGD Stand der Abteilung Interactive Multimedia Appliances ausprobiert werden und fand auch Erwähnung in der SWR Berichterstattung zur Messe.
Die Software besteht aus drei wesentlichen Komponenten:
- Einer Android Applikation inkl. 3D Darstellung des zu steuernden Raumes
- Einer Server Komponente zur Anbindung an eine bestehende Software-Plattform
- Einem Kommunikationsprotokoll zwischen der Android App und Server
 |
| Das nicht ganz ernst gemeinte App Logo. |
Ein paar Hintergrundinfos
Das Fraunhofer-Institut für Graphische Datenverarbeitung in Darmstadt unterhält eine Installation einer Wohnumgebung zum Forschen an und zum Testen von intelligenten Systemen, welche den Alltag eines darin wohnenden Menschen unterstützen und bereichern sollen. Diese Wohnungsimulation wird von uns "Das Lab" genannt.
Das Lab dient als Demo-Szenario für die AHC Android App und wird mittels eines vereinfachten 3D Modells durch die App dargestellt. Für die Darstellung dienen Daten, welche aus der universAAL Softwareplattform ausgelesen werden: Die Abteilung Interactive Multimedia Appliances in der ich seit 2008 als Wissenschaftliche-Hilfskraft tätig bin entwickelt die o.g. Softwareplattform universAAL. Die Plattform zu beschreiben würde an dieser Stelle den Rahmen sprengen.
In Kürze zusammengefasst und für das Verständnis der Funktionsweise des AHC wichtig ist, dass diese Plattform eine Abstraktion und Komposition von Sensoren unterschiedlichster Geräte, Protokolle und Hersteller bereitstellt. Die von den Sensoren gelieferten Daten werden in einem situationsabhängigen Kontext verarbeitet und können z.B. dazu genutzt werden sich proaktiv auf die Bedürfnisse eines Benutzers einzustellen. Das bedeutet, dass die Umgebung unter Anderem Verhaltensmuster erkennen und darauf reagieren kann, wie z.B. wenn man sich abends auf das Sofa legt, so wird automatisch das Licht gedämmt. Andererseits kann der Benutzer seine Umgebung und die darin befindlichen Geräte steuern ohne deren Repertoire an Funktionen genau zu kennen. Zum Beispiel kann der Benutzer frei in den Raum sagen "Ich möchte Musik hören", doch im Wohnzimmer ist nirgends eine HiFi-Anlage installiert: Die Plattform kennt jedoch die Möglichkeiten des vorhandenen Fernsehers und weiß, dass dieser ebenso in der Lage ist Musik abzuspielen. Somit schaltet sie diesen ein und spielt auf diesem die gewünschte Musik ab. Die Kenntnis der Plattform über das physikalische Vorhandensein des Fernsehers, sowie seines Funktionsumfangs basiert auf einer internen ontologischen Darstellung der Umgebung, in welcher universAAL eingesetzt wird.
Ändert sich somit die Ontologie - Geräte kommen hinzu / werden entfernt, ändern ihre Position, werden ein- / ausgeschaltet, etc. - reflektiert sich dieser Sachverhalt auf die 3D Darstellung der AHC Android App.
UniversAALs ontologische Darstellung gruppiert Geräte, Inventar und die Umgebung selbst durch die Angabe von Typen. Jeder Typ (Fernseher, HiFi Anlage, Licht etc.) wird durch eine Type-URI repräsentiert. Das jeweilige Gerät hingegen wird durch eine eindeutige Device-URI registriert.
Nun werden beim Aufbereiten der Ontologie für die 3D Darstellung in der Android App eben diese URIs ausgewertet. Die AHC Android App hält 3D Modelle verschiedener Geräte, welche im Lab installiert sind, als darstellbare Ressourcen bereit. Diese Nachbildungen habe ich während anderer Arbeiten am Fraunhofer IGD mit 3ds max modelliert (siehe z.B. IGD - Meine Arbeiten Teil 1 -- Nursing Service ). Die AHC Android App arbeitet beim Aufbereiten zuerst die Device-URIs ab: Ist einer Device-URI ein 3D Modell zugeordnet so wird dieses verwendet und damit eine möglichst exakte Nachbildung der reellen Szene realisiert. Ist kein 3D Modell für eine Device-URI vorhanden, so wird die Type-URI zu Rate gezogen und ein Platzhalter-Objekt mit den entsprechenden Dimensionen des reellen Gerätes gesetzt. Dieses Dummy Objekt wird mit einer Textur ausgestattet, welches es dem Benutzer ermöglicht trotzdem zu erkennen, um welche Art von Gerät es sich handelt. Scheitert der Vergleich beider URI-Typen, so wird ein allgemeiner Platzhalter verwendet - z.B. auch für die Darstellung nicht benutzbarer Geräte (Die Darstellung dieser Platzhalter ist über ein Menü deaktivierbar und man schafft damit Übersicht in der Szene). Damit wurde eine breite Kompatibilität geschaffen, welche in der Kürze der Entwicklungszeit es trotz diverser Eventualitäten möglich macht, auch unbekannte Geräte zu steuern.
Das Lab dient als Demo-Szenario für die AHC Android App und wird mittels eines vereinfachten 3D Modells durch die App dargestellt. Für die Darstellung dienen Daten, welche aus der universAAL Softwareplattform ausgelesen werden: Die Abteilung Interactive Multimedia Appliances in der ich seit 2008 als Wissenschaftliche-Hilfskraft tätig bin entwickelt die o.g. Softwareplattform universAAL. Die Plattform zu beschreiben würde an dieser Stelle den Rahmen sprengen.
 |
| Darstellung des 3D Modells des "Labs" am Fraunhofer IGD in Darmstadt. |
Bezug zu meiner Arbeit
Diese Ontologie wird von der AHC dazu genutzt geometrische Informationen über die Welt - hier das Lab - sowie den darin befindlichen Geräten zu erhalten. Die Schnittstelle zwischen der Android App und der universAAL Plattform bildet der AHC Server. Dieser läuft, vereinfacht gesagt, auf dem Rechner, welcher die Plattform ausführt. Er übersetzt die Daten, welche von der AHC Android App kommen - welche wiederum mittels des von mir entwickelten Kommunikationsprotokolls übertragen werden - in die Kontext-Ereignisse, welche von universAAL verstanden werden. Gleichzeitig erfragt er Fakten der Umgebungsontologie und sendet diese an die AHC Android App.Ändert sich somit die Ontologie - Geräte kommen hinzu / werden entfernt, ändern ihre Position, werden ein- / ausgeschaltet, etc. - reflektiert sich dieser Sachverhalt auf die 3D Darstellung der AHC Android App.
UniversAALs ontologische Darstellung gruppiert Geräte, Inventar und die Umgebung selbst durch die Angabe von Typen. Jeder Typ (Fernseher, HiFi Anlage, Licht etc.) wird durch eine Type-URI repräsentiert. Das jeweilige Gerät hingegen wird durch eine eindeutige Device-URI registriert.
Nun werden beim Aufbereiten der Ontologie für die 3D Darstellung in der Android App eben diese URIs ausgewertet. Die AHC Android App hält 3D Modelle verschiedener Geräte, welche im Lab installiert sind, als darstellbare Ressourcen bereit. Diese Nachbildungen habe ich während anderer Arbeiten am Fraunhofer IGD mit 3ds max modelliert (siehe z.B. IGD - Meine Arbeiten Teil 1 -- Nursing Service ). Die AHC Android App arbeitet beim Aufbereiten zuerst die Device-URIs ab: Ist einer Device-URI ein 3D Modell zugeordnet so wird dieses verwendet und damit eine möglichst exakte Nachbildung der reellen Szene realisiert. Ist kein 3D Modell für eine Device-URI vorhanden, so wird die Type-URI zu Rate gezogen und ein Platzhalter-Objekt mit den entsprechenden Dimensionen des reellen Gerätes gesetzt. Dieses Dummy Objekt wird mit einer Textur ausgestattet, welches es dem Benutzer ermöglicht trotzdem zu erkennen, um welche Art von Gerät es sich handelt. Scheitert der Vergleich beider URI-Typen, so wird ein allgemeiner Platzhalter verwendet - z.B. auch für die Darstellung nicht benutzbarer Geräte (Die Darstellung dieser Platzhalter ist über ein Menü deaktivierbar und man schafft damit Übersicht in der Szene). Damit wurde eine breite Kompatibilität geschaffen, welche in der Kürze der Entwicklungszeit es trotz diverser Eventualitäten möglich macht, auch unbekannte Geräte zu steuern.
 |
| Die Wohnzimmerlampe stellt in diesem Szenario Ein- / Aus-Funktionen zur Verfügung. |
Das Android Home Control erweitert die kontextsensitive und proaktive Interaktion mit der Wohnumgebung, welche die universAAL Plattform liefert, durch eine weitere Möglichkeit: Die direkte Steuerung.
Wie bereits erwähnt kennt die universAAL Plattform die einzelnen installierten Geräte der Wohnumgebung, sowie deren Funktionsmöglichkeiten. Wählt der Benutzer ein reaktives Gerät in der virtuellen 3D Darstellung aus, so fordert die Android App vom AHC-Server eine Dienstliste für das entsprechende Gerät via Geräte-ID an - den oben erwähnten Device-URIs.
Der AHC-Server erfragt nun wiederum bei der universAAL Plattform, welche Funktionen sie für genau dieses Gerät kennt und stellt eine Dienstliste zusammen. Jeder Eintrag in der Dienstliste besteht aus einem Funktionsnamen (Fernseher an, Fernseher aus, leiser, lauter, etc.) und den entsprechenden Datenstrukturen (z.B. boolschen Werten für ein / aus, Zahlenwerten für die gewünschte Lautstärke, etc.). Die Liste wird an die AHC Android App übertragen und dort angezeigt. Wählt der Benutzer nun eine der möglichen Funktionen aus, so wird ein Aktionskommando an den AHC-Server gesendet und an die universAAL Plattform übersetzt. Nun erfolgt noch eine Rückmeldung vom AHC-Server an die App: Ist diese eine Fehlermeldung, so wird das dem Benutzer angezeigt.
Enthält sie jedoch eine Erfolgsmeldung, geschehen zweierlei Dinge.
Wie bereits erwähnt kennt die universAAL Plattform die einzelnen installierten Geräte der Wohnumgebung, sowie deren Funktionsmöglichkeiten. Wählt der Benutzer ein reaktives Gerät in der virtuellen 3D Darstellung aus, so fordert die Android App vom AHC-Server eine Dienstliste für das entsprechende Gerät via Geräte-ID an - den oben erwähnten Device-URIs.
Der AHC-Server erfragt nun wiederum bei der universAAL Plattform, welche Funktionen sie für genau dieses Gerät kennt und stellt eine Dienstliste zusammen. Jeder Eintrag in der Dienstliste besteht aus einem Funktionsnamen (Fernseher an, Fernseher aus, leiser, lauter, etc.) und den entsprechenden Datenstrukturen (z.B. boolschen Werten für ein / aus, Zahlenwerten für die gewünschte Lautstärke, etc.). Die Liste wird an die AHC Android App übertragen und dort angezeigt. Wählt der Benutzer nun eine der möglichen Funktionen aus, so wird ein Aktionskommando an den AHC-Server gesendet und an die universAAL Plattform übersetzt. Nun erfolgt noch eine Rückmeldung vom AHC-Server an die App: Ist diese eine Fehlermeldung, so wird das dem Benutzer angezeigt.
Enthält sie jedoch eine Erfolgsmeldung, geschehen zweierlei Dinge.
- Der aktuelle Status des Gerätes wird in der 3D Umgebung direkt wiedergegeben (z.B. Glühbirnensymbol leuchtet auf).
- In der reellen Umgebung führt das entsprechende Gerät die Aktion aus (z.B. Licht geht an).
Der Benutzer erhält in der weitesten Zoomstufe einen Überblick über die gesamte Wohnumgebung und ist somit in der Lage auch Geräte zu steuern, welche sich nicht in dem Raum befinden, in welchem sich der Benutzer aktuell selbst befindet. Die direkte Reflexion des Weltzustandes auf die 3D Darstellung informiert den Benutzer über Erfolg, oder Misserfolg seiner Aktion. Dies ermöglicht zeitgleich auch die Überwachung von Geräten, welche sich nicht im direkten Sichtfeld des Benutzers befinden.
Steuern lässt sich die AHC Android App bequem über den Touchscreen. Fingerbewegungen nach links und rechts erlauben das drehen und neigen der Kamera um einen festen Fokuspunkt, ohne dabei die jeweilige Seitenansicht verlassen zu können. Das soll vor allem auch nicht so versierten Benutzern die Navigation und Orientierung erleichtern. Möchte der Nutzer einen 90° Schwenk zu einer anderen Seitenansicht durchführen, so stehen ihm entsprechende Tasten in der grafischen Oberfläche zur Verfügung. Eine Windrose gibt des Weiteren Rückmeldung über die aktuelle Position der Kamera im Raum. Die Zoomstufe kann mittels der populären "Pinch-To-Zoom" Geste geändert werden. Reset Tasten für die Drehung, sowie den Zoom befördern die Kamera zu ihrem jeweiligen Ausgangspunkt zurück.
Steuern lässt sich die AHC Android App bequem über den Touchscreen. Fingerbewegungen nach links und rechts erlauben das drehen und neigen der Kamera um einen festen Fokuspunkt, ohne dabei die jeweilige Seitenansicht verlassen zu können. Das soll vor allem auch nicht so versierten Benutzern die Navigation und Orientierung erleichtern. Möchte der Nutzer einen 90° Schwenk zu einer anderen Seitenansicht durchführen, so stehen ihm entsprechende Tasten in der grafischen Oberfläche zur Verfügung. Eine Windrose gibt des Weiteren Rückmeldung über die aktuelle Position der Kamera im Raum. Die Zoomstufe kann mittels der populären "Pinch-To-Zoom" Geste geändert werden. Reset Tasten für die Drehung, sowie den Zoom befördern die Kamera zu ihrem jeweiligen Ausgangspunkt zurück.
Da es sich bei dem Projekt um ein Ein-Mann-Praktikum während des Sommersemester gehandelt hat, für welches ich ca. vier Monate Zeit hatte (neben anderen Vorlesungen und privaten Verpflichtungen), ist das AHC Projekt rein als Demonstrator bzw. "Proof of concept" umgesetzt worden und damit natürlich noch stark entwicklungsfähig. Stolz macht mich, dass die gesamte Android Home Control Infrastruktur sehr robust und zuverlässig arbeitet, so dass sie bereits für weitere Praktikas anderer Studenten genutzt wurde und in meinen Notenspiegel mit einer 1.0 als Note einfloss.
Zusammengefasst
 |
| Menü zur Client-Server Kommunikation. |
- Anbindung einer 3D EngineEs wurde die jpct-ae open source Engine genutzt.
- Anbindung des Android-Tablets (genutzt wurde das Samsung Galaxy Tab mit Android 2.2 Froyo) an die vorhandene universAAL PlattformDies geschieht mittels einer TCP/IP Wireless-LAN Verbindung über ein eigens entwickeltes Kommunikationsprotokoll zwischen dem AHC Server und der AHC App. Dieses Protokoll sendet ein Containertoken zwischen Klient und Server, welcher alle serialisierbaren Objekte enthalten kann, plus einiger obligatorischen Metadaten. Somit ist das Protokoll für weitere Projekte gut erweiterbar. Die kabellose Verbindung zum AHC Server ermöglicht fast unbeschränkte Bewegungsfreiheit im zu steuernden Raum.
- Entwicklung eines Formates zur Übermittlung der Räum- und Geräte-DarstellungDie universAAL Plattform nutzt eine komplexe Ontologie, deren Daten, welche für die Darstellung der Umgebung essentiell sind, in ein XML Format ausgelesen werden. Dazu wird der X3D Standard genutzt, der unter anderem vom InstantPlayer direkt gelesen und angezeigt werden kann. Die AHC Android App wurde mit einem XML / X3D Parser ausgestattet (basierend auf der Simple Api for XML), welcher die vom AHC Server gesendeten X3D Daten einlesen und für die Darstellung mittels der jpct-ae Engine aufbereiten kann.
- Entwicklung einer intuitiven SteuerungDer Benutzer kann sich um einen festen Fokuspunkt mittels Touch-Gesten orientieren, indem er die Kamera schwenkt und kippt und mit einer Zweifinger-Geste in die Szene heranzoomt. Dies erleichtert das Selektieren teils, oder gänzlich verdeckter Geräte. Die Auswahl erfolgt mittels Berührung.
- Entwicklung einer GUI aus den bereitgestellten GerätefunktionsdatenBei jeder Geräteauswahl wird das Menü neu aufgebaut, was sicherstellt, dass auch Funktionsumfangsänderungen möglichst zeitnah für die AHC App aktualisiert werden können.
Die Android Home Control App konnte auch auf der CeBit 2012 am Fraunhofer IGD Stand der Abteilung Interactive Multimedia Appliances ausprobiert werden und fand auch Erwähnung in der SWR Berichterstattung zur Messe.
Ein großer Dank von meiner Seite aus geht an meine beiden Betreuer Andreas Braun und Alexander Marinc, welche mich mit konstruktiver Kritik und erschöpfenden Wunschvorstellungen zu durchprogrammierten Nächten getrieben, mich aber auch an den richtigen Stellen gebremst haben! ;-)
Freitag, 29. April 2011
IGD - Meine Arbeiten Teil 3 -- "Intelligenter Helfer"
Der dritte Teil dieser Serie befasst sich mit der Arbeit an einem helfenden Haushaltsroboter. Die Ausbeute an Bildmaterial für diesen Artikel fällt leider recht mager aus und das hat folgenden Grund:
Der genaue Einsatz dieser Arbeit ist mir nicht bekannt (gewesen), es hieß nur: "Wir brauchen einen Roboter, welcher nett aussieht und was 'sinnvolles' und hilfreiches macht" - so, oder so ähnlich war der Wortlaut. Der Roboter unterlag somit keinen technischen, oder optischen Vorgaben, was mir freie Hand bei der Gestaltung gab.
Aus dem Grund entstand die Szene in einem so rapiden Tempo, dass ich damals nur zwei Renderings von dem hier gezeigten Roboter erstellt habe. Das eine Bild, welches den Roboter in einer Ausgangs- bzw. Idle-pose zeigte, hat nie die Festplatte gesehen. Das andere Bild seht ihr jetzt.

Die Wohnzimmerszene ist bereits aus den früheren Teilen dieser Artikelserie bekannt und wurde für dieses Rendering nicht weiter bearbeitet, sondern nur "recycelt". Man erkennt immer noch die recht leeren Regale, was darin begründet liegt, dass ich die Szene noch während der Entwicklung für verschiedene Nebenaufträge "missbraucht" habe.
Der Roboter selbst entstand innerhalb von ca. zwei Stunden und erinnert nicht zufällig an Eve aus dem Pixar / Walt Disney Animationsfilm "WALL-E". Ich glaube ich habe den Film sogar noch am Vortag geschaut und fand das Design sehr passend.
Somit skizzierte ich den Roboter kurzerhand in meinen Collageblock und bildete die symmetrische, runde Form des Roboters mit Splines in 3ds max nach, welche ich im Anschluss mit einer Dreh-Extrusion in ein Polygonmodell umwandelte.
Die Skizze habe ich mir glücklicherweise aufgehoben!

Die Teekanne ist jedem, der sich ein wenig mit Computergrafik befasst sicherlich bekannt. Die Tasse und das Tablett sind meine kleinen Kreationen.
Der Roboter besteht außerdem noch aus den Armen, welche recht einfach aus Sphären und Zylindern zusammengesetzt und hierarchisch miteinander verbunden sind, so dass die Gestaltung der Pose leichter viel.
Bones habe ich keine verwendet, denn für den gewünschten Zweck wäre die Arbeit damit zu aufwendig.
Texturen besitzt der Roboter, bis auf sein freundliches Antlitz, keine. Seine Oberfläche wurde durch Materialien definiert,
Interessanterweise habe ich mit dem oben gezeigten Rendering auch auf Anhieb das Licht, die Kameraposition und die Gesamtstimmung nach dem Geschmack meines "Auftraggebers" eingefangen.
Da die Render-Einstellungen durch die Parallelprojekte bereits fertig abgestimmt waren, war die Szene im ersten Durchlauf im Kasten.
Ich hoffe sie gefällt euch!
Bis zum nächsten Teil meiner Arbeiten am Fraunhofer IGD.
Der genaue Einsatz dieser Arbeit ist mir nicht bekannt (gewesen), es hieß nur: "Wir brauchen einen Roboter, welcher nett aussieht und was 'sinnvolles' und hilfreiches macht" - so, oder so ähnlich war der Wortlaut. Der Roboter unterlag somit keinen technischen, oder optischen Vorgaben, was mir freie Hand bei der Gestaltung gab.
Aus dem Grund entstand die Szene in einem so rapiden Tempo, dass ich damals nur zwei Renderings von dem hier gezeigten Roboter erstellt habe. Das eine Bild, welches den Roboter in einer Ausgangs- bzw. Idle-pose zeigte, hat nie die Festplatte gesehen. Das andere Bild seht ihr jetzt.

Die Wohnzimmerszene ist bereits aus den früheren Teilen dieser Artikelserie bekannt und wurde für dieses Rendering nicht weiter bearbeitet, sondern nur "recycelt". Man erkennt immer noch die recht leeren Regale, was darin begründet liegt, dass ich die Szene noch während der Entwicklung für verschiedene Nebenaufträge "missbraucht" habe.
Der Roboter selbst entstand innerhalb von ca. zwei Stunden und erinnert nicht zufällig an Eve aus dem Pixar / Walt Disney Animationsfilm "WALL-E". Ich glaube ich habe den Film sogar noch am Vortag geschaut und fand das Design sehr passend.
Somit skizzierte ich den Roboter kurzerhand in meinen Collageblock und bildete die symmetrische, runde Form des Roboters mit Splines in 3ds max nach, welche ich im Anschluss mit einer Dreh-Extrusion in ein Polygonmodell umwandelte.
Die Skizze habe ich mir glücklicherweise aufgehoben!

Die Teekanne ist jedem, der sich ein wenig mit Computergrafik befasst sicherlich bekannt. Die Tasse und das Tablett sind meine kleinen Kreationen.
Der Roboter besteht außerdem noch aus den Armen, welche recht einfach aus Sphären und Zylindern zusammengesetzt und hierarchisch miteinander verbunden sind, so dass die Gestaltung der Pose leichter viel.
Bones habe ich keine verwendet, denn für den gewünschten Zweck wäre die Arbeit damit zu aufwendig.
Texturen besitzt der Roboter, bis auf sein freundliches Antlitz, keine. Seine Oberfläche wurde durch Materialien definiert,
Interessanterweise habe ich mit dem oben gezeigten Rendering auch auf Anhieb das Licht, die Kameraposition und die Gesamtstimmung nach dem Geschmack meines "Auftraggebers" eingefangen.
Da die Render-Einstellungen durch die Parallelprojekte bereits fertig abgestimmt waren, war die Szene im ersten Durchlauf im Kasten.
Ich hoffe sie gefällt euch!
Bis zum nächsten Teil meiner Arbeiten am Fraunhofer IGD.
Donnerstag, 14. April 2011
IGD - Meine Arbeiten Teil 2 -- "Was machen die Kühe?"
Eines Tages beauftragte man mich für eine Ortungssystem-Demo eine Kuh zu entwerfen.
Wie das Endergebnis geworden ist und welchen Problemen ich begegnet bin, möchte ich im heutigen Artikel schildern.
Trivia
Modellierung und Texturierung
 Da ich vor diesem Modell nur recht technische Modelle bzw. Sach-Modelle erstellt habe, war so ein (relativ komplexes) organisches Modell durchaus eine kleine Herausforderung für mich. Zusätzlich kannte ich Kühe bestenfalls aus dem Fernsehen - als deutscher (Vor-) Stadtmensch laufen einem nicht so häufig Kühe über den Weg. Somit musste ich mir meine Referenzen erstmal zusammensuchen.
Da ich vor diesem Modell nur recht technische Modelle bzw. Sach-Modelle erstellt habe, war so ein (relativ komplexes) organisches Modell durchaus eine kleine Herausforderung für mich. Zusätzlich kannte ich Kühe bestenfalls aus dem Fernsehen - als deutscher (Vor-) Stadtmensch laufen einem nicht so häufig Kühe über den Weg. Somit musste ich mir meine Referenzen erstmal zusammensuchen.
Internet sei Dank kommt man aber auch ohne große Mühe an Referenzmaterial in Form von Bildern und Videos.

Leider fiel mir viel zu spät ein, dass es auch Plastik-Modelle von Kühen im Spielzeug- und Modelleisenbahn-Laden gibt.
Gestützt auf unzählige Fotographien und Videos von glücklichen Kühen fing ich somit an zu modellieren und arbeitete mich von der Schnauze zum Hinterteil "vor".
 Eine wesentliche Neuerung für mich und eine absolute Wohltat zugleich war mein erstmaliger Einsatz einer 3DConnexion SpaceNavigator 3D-Maus.
Eine wesentliche Neuerung für mich und eine absolute Wohltat zugleich war mein erstmaliger Einsatz einer 3DConnexion SpaceNavigator 3D-Maus.
Dieses schmucke Stück eines Eingabegerätes vereinfacht die Navigation im virtuellen Raum und macht es derart intuitiv, dass ich heut zu Tage gar nicht mehr ohne ein solches Gerät modellieren möchte.
Die SpaceNavigator-Maus ist zwar eine "Einsteiger"-3D-Maus, doch für die meisten Zwecke absolut ausreichend und deutlich günstiger als eine SpacePilot Pro, oder SpaceExplorer. Wer gerne und viel modelliert, dem kann ich eine 3D Maus absolut ans Herz legen. Nutzbar ist sie unter anderem auch mit Google Earth, Photoshop, Autodesk Maya und vielen anderen Programmen.
Die Kuh besitzt nur zwei Texturen: Eine für die Augen, eine für das fleckige Fell. Beide Texturen wurden mit Photoshop erstellt.
Da das Modell für die Echtzeit-Renderumgebung des Fraunhofer IGDs exportiert werden musste, und das Export-PlugIn für 3ds max zum damaligen Zeitpunkt noch arge Probleme mit komplexen UVW-Maps hatte, musste ich etwas tricksen. So habe ich das Fell mittels einer, um 45 Grad auf der Längsachse der Kuh verdrehten, Projektionsplane gemappt. Nicht gerade die eleganteste Lösung, doch eine, welche ein relativ angenehm asymmetrisch-organisches Ergebnis lieferte und dabei den Exporter nicht überforderte.
Die Schnauze, die Hufe, sowie das Euter bekamen "per-vertex" Farben zugeteilt. Dadurch erreichte ich ein schnell gemachtes und trotzdem ansprechendes Ergebnis.
Rigging und Animation
Nachdem das 3D Modell der Kuh fertig modelliert war, musste das nette Rind noch laufen lernen - die Kühe sollten schließlich in der Demo frei über die Weide traben und vom Ortungssystem überwacht werden.
Mir wurde während der Arbeit bewusst, dass ich in Sachen Rigging und Animation noch viel dazulernen musste. Ich konnte zwar, wie im ersten Teil dieser Artikelserie gesagt, ohne Probleme fertige, organische Modelle anpassen, doch ein komplett jungfräuliches Modell selbst zu riggen und zu animieren, fiel mir doch reichlich schwer.
Um menschenähnliche Gestalten zu riggen und zu animieren enthielt 3ds max 2009 zwar ein gut gemachtes Biped-Skelett, doch für eine Kuh, welche auf vier Beinen läuft, war das so nicht praktikabel. Aus dem Zweibeiner (Biped) musste ein Vierbeiner (Quadruped) inkl. Schwanz gebaut werden.
Nachdem diese Arbeit erledigt war, konnte dann schließlich und endlich das Skelett per Skin-Modifier an das Polygonmesh gekoppelt und die Kuh animiert werden.
Auch hier zeigte sich: Der Umgang mit dem Skin-Modifier muss auch erstmal erlernt werden. Kaum dachte ich alle Vertices an die richtigen Bones mit der entsprechenden Gewichtung gemappt zu haben, schon wurde aus irgend einem Grund ein Polygon am Schwanz der Kuh verändert, wenn die Kuh ihren Kopf bewegte.
Für die Bewegungsabläufe (stehen, sitzen, laufen) nutzte ich als Referenz verschiedene Videoportale, denn auch hier gilt: Normalerweise laufen keine Kühe durch Büroräume.
Ich war sehr überrascht, wie viele Details man doch an so einem unscheinbaren Tier entdeckt, wenn man es über einen längeren Zeitraum "intensiv" studiert. Sehr interessant fand ich die recht steife Vorwärtsbewegung der Hinterläufe (hat meiner Meinung nach Ähnlichkeit mit laufen auf Stelzen).
Ob das Ergebnis überzeugt, könnt ihr euch in folgendem Video ansehen:
Die stehende und sitzende Kuh will ich an dieser Stelle nicht zeigen, da zum Einen die Stehpose recht langweilig und zum Anderen die Sitzpose eine Katastrophe ist! Bei letzterer zeigte sich, wie viel Know-How man doch für ein ansprechendes und wiederverwendbares Rigging-Ergebnis genötigt.
Das war Teil zwei der Artikelserie zu meinen Arbeiten am Fraunhofer IGD.
Im nächsten Teil zeige ich dann mehr "technisches" Material.
Kritik, Kommentare und Anregungen sind sehr willkommen!
"Martin, wir brauchen Kühe!"
Wie das Endergebnis geworden ist und welchen Problemen ich begegnet bin, möchte ich im heutigen Artikel schildern.
Trivia
- Da ich mit der Demo per se nicht viel zu tun hatte, kann ich auch nicht viel dazu sagen. Was ich weiß ist, dass eine Kuh für ein virtuelles "Bauernhof"-Szenario gebraucht wurde, bei dem der virtuelle Bauer immer seine Schäfchen bzw. in dem Fall Kühe auf der weitläufigen Weide im Blick hat - inklusive all ihrer Vitalzeichen.
- Da die Demo eine Echtzeitsimulation sein sollte, ging es beim Modellieren auch darum einen optimalen Kompromiss zwischen Polygonanzahl und Detailgrad zu finden. Die auf den Bildern sichtbare Kuh hat in der Summe rund 6.000 Polygone.
- Die Modellierung, Texturierung und Animation habe ich mit 3ds max 2009 gemacht.
- Für einige der Screenshots in diesem Artikel habe ich das brandneue 3ds max 2012 in der "Education"-Version genutzt. Absolute Empfehlung - beste Version seit 3ds max 2009.
- Während der mehrwöchigen Arbeit an dem Modell (meine Wochenarbeitszeit als HiWi ist wegen der lächerlichen 400 Euro Grenze stark beschränkt - danke Vater Staat) wurde ich laufend mit einem herzlichen "Was machen die Kühe?" begrüßt! ^_^'
Modellierung und Texturierung
 Da ich vor diesem Modell nur recht technische Modelle bzw. Sach-Modelle erstellt habe, war so ein (relativ komplexes) organisches Modell durchaus eine kleine Herausforderung für mich. Zusätzlich kannte ich Kühe bestenfalls aus dem Fernsehen - als deutscher (Vor-) Stadtmensch laufen einem nicht so häufig Kühe über den Weg. Somit musste ich mir meine Referenzen erstmal zusammensuchen.
Da ich vor diesem Modell nur recht technische Modelle bzw. Sach-Modelle erstellt habe, war so ein (relativ komplexes) organisches Modell durchaus eine kleine Herausforderung für mich. Zusätzlich kannte ich Kühe bestenfalls aus dem Fernsehen - als deutscher (Vor-) Stadtmensch laufen einem nicht so häufig Kühe über den Weg. Somit musste ich mir meine Referenzen erstmal zusammensuchen.Internet sei Dank kommt man aber auch ohne große Mühe an Referenzmaterial in Form von Bildern und Videos.

Leider fiel mir viel zu spät ein, dass es auch Plastik-Modelle von Kühen im Spielzeug- und Modelleisenbahn-Laden gibt.
Gestützt auf unzählige Fotographien und Videos von glücklichen Kühen fing ich somit an zu modellieren und arbeitete mich von der Schnauze zum Hinterteil "vor".
Eine wesentliche Neuerung für mich und eine absolute Wohltat zugleich war mein erstmaliger Einsatz einer 3DConnexion SpaceNavigator 3D-Maus.Dieses schmucke Stück eines Eingabegerätes vereinfacht die Navigation im virtuellen Raum und macht es derart intuitiv, dass ich heut zu Tage gar nicht mehr ohne ein solches Gerät modellieren möchte.
Die SpaceNavigator-Maus ist zwar eine "Einsteiger"-3D-Maus, doch für die meisten Zwecke absolut ausreichend und deutlich günstiger als eine SpacePilot Pro, oder SpaceExplorer. Wer gerne und viel modelliert, dem kann ich eine 3D Maus absolut ans Herz legen. Nutzbar ist sie unter anderem auch mit Google Earth, Photoshop, Autodesk Maya und vielen anderen Programmen.
 |  |  |
Die Kuh besitzt nur zwei Texturen: Eine für die Augen, eine für das fleckige Fell. Beide Texturen wurden mit Photoshop erstellt.
Da das Modell für die Echtzeit-Renderumgebung des Fraunhofer IGDs exportiert werden musste, und das Export-PlugIn für 3ds max zum damaligen Zeitpunkt noch arge Probleme mit komplexen UVW-Maps hatte, musste ich etwas tricksen. So habe ich das Fell mittels einer, um 45 Grad auf der Längsachse der Kuh verdrehten, Projektionsplane gemappt. Nicht gerade die eleganteste Lösung, doch eine, welche ein relativ angenehm asymmetrisch-organisches Ergebnis lieferte und dabei den Exporter nicht überforderte.
Die Schnauze, die Hufe, sowie das Euter bekamen "per-vertex" Farben zugeteilt. Dadurch erreichte ich ein schnell gemachtes und trotzdem ansprechendes Ergebnis.
 |  |
Rigging und Animation
Nachdem das 3D Modell der Kuh fertig modelliert war, musste das nette Rind noch laufen lernen - die Kühe sollten schließlich in der Demo frei über die Weide traben und vom Ortungssystem überwacht werden.
Mir wurde während der Arbeit bewusst, dass ich in Sachen Rigging und Animation noch viel dazulernen musste. Ich konnte zwar, wie im ersten Teil dieser Artikelserie gesagt, ohne Probleme fertige, organische Modelle anpassen, doch ein komplett jungfräuliches Modell selbst zu riggen und zu animieren, fiel mir doch reichlich schwer.
Um menschenähnliche Gestalten zu riggen und zu animieren enthielt 3ds max 2009 zwar ein gut gemachtes Biped-Skelett, doch für eine Kuh, welche auf vier Beinen läuft, war das so nicht praktikabel. Aus dem Zweibeiner (Biped) musste ein Vierbeiner (Quadruped) inkl. Schwanz gebaut werden.
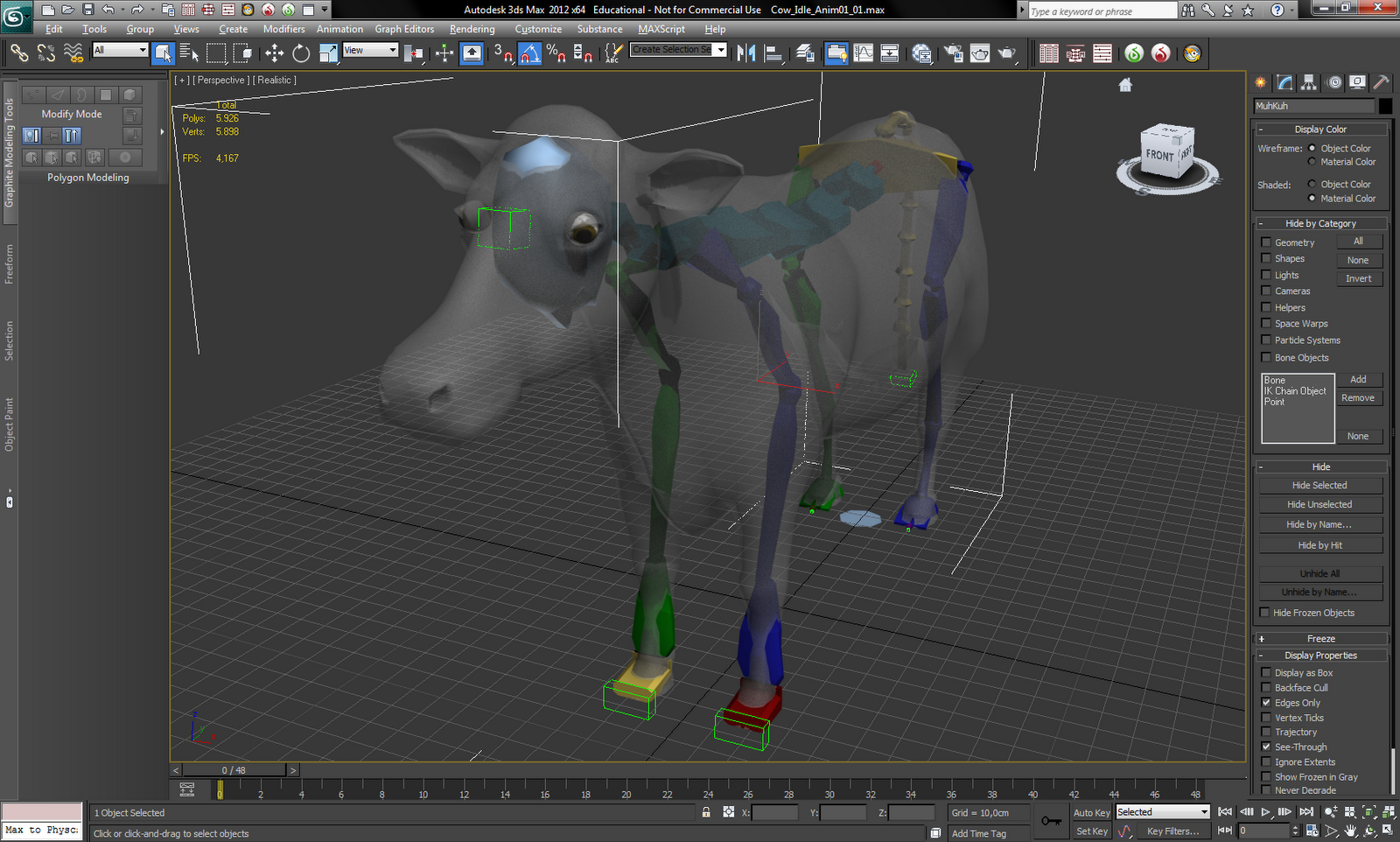 |  |
Nachdem diese Arbeit erledigt war, konnte dann schließlich und endlich das Skelett per Skin-Modifier an das Polygonmesh gekoppelt und die Kuh animiert werden.
Auch hier zeigte sich: Der Umgang mit dem Skin-Modifier muss auch erstmal erlernt werden. Kaum dachte ich alle Vertices an die richtigen Bones mit der entsprechenden Gewichtung gemappt zu haben, schon wurde aus irgend einem Grund ein Polygon am Schwanz der Kuh verändert, wenn die Kuh ihren Kopf bewegte.
Für die Bewegungsabläufe (stehen, sitzen, laufen) nutzte ich als Referenz verschiedene Videoportale, denn auch hier gilt: Normalerweise laufen keine Kühe durch Büroräume.
Ich war sehr überrascht, wie viele Details man doch an so einem unscheinbaren Tier entdeckt, wenn man es über einen längeren Zeitraum "intensiv" studiert. Sehr interessant fand ich die recht steife Vorwärtsbewegung der Hinterläufe (hat meiner Meinung nach Ähnlichkeit mit laufen auf Stelzen).
Ob das Ergebnis überzeugt, könnt ihr euch in folgendem Video ansehen:
Die stehende und sitzende Kuh will ich an dieser Stelle nicht zeigen, da zum Einen die Stehpose recht langweilig und zum Anderen die Sitzpose eine Katastrophe ist! Bei letzterer zeigte sich, wie viel Know-How man doch für ein ansprechendes und wiederverwendbares Rigging-Ergebnis genötigt.
Das war Teil zwei der Artikelserie zu meinen Arbeiten am Fraunhofer IGD.
Im nächsten Teil zeige ich dann mehr "technisches" Material.
Kritik, Kommentare und Anregungen sind sehr willkommen!
Donnerstag, 31. März 2011
IGD - Meine Arbeiten Teil 1 -- Nursing Service
Seit August 2008 arbeite ich nun als Student beim Fraunhofer-Institut für Graphische Datenverarbeitung (IGD) in Darmstadt und möchte euch nun einige meiner visuellen Arbeiten präsentieren.
Dazu habe ich freundlicherweise die Erlaubnis erhalten einen Teil meiner Arbeit hier auf meinem Blog zu veröffentlichen und ein wenig über den Entstehungsprozess zu berichten.
Nursing Service - Storyboard-Actionsequenz
Beginnen möchte ich die mehrteilige Präsentation mit einer in Bilderserie, welche für ein Projekt-Proposal ende des Jahres 2008 erstellt und genutzt wurde.
Es handelt sich bei dieser Bilderserie um ein Aktionssequenz über fünf Bilder, welche einen eingehenden Anruf eines Altenpflegers bei einem älteren Herren, über die im Haus verfügbaren Multimedia-Geräte und die intelligente Lichtsteuerung, sowie die Absprache eines Termins zeigt.
Speziell wird hier eine Videokonferenz über den Fernseher mit eingebauter Videokamera zwischen Altenpfleger und der zu betreuenden Person geführt.
Die Sequenz

Ein älterer Herr sitzt zu Hause auf dem Sofa und liest bei gedimmtem Licht und eingeschalteter Leseleuchte ein Buch.

Plötzlich schaltet sich der Fernseher ein und zeigt eine Nachricht an, welche einen Anruf vom Altenpfleger verkündet. Um die Aufmerksamkeit noch stärker auf sich zu lenken und die Art der aktuellen Situation zu verdeutlichen, wird zusätzlich ein blaues Licht hinter dem Fernseher aktiviert.

Der ältere Herr ist mit dem Anruf einverstanden und tätigt eine Annahme-Geste, indem er seine Hand mit der Handfläche nach oben hochhebt. Dies hat zur Folge, dass die Raumbeleuchtung verstärkt...

... und die Videokonferenz gestartet wird. Auf dem Fernseher sieht man den Altenpfleger (schönen Gruß an Felix! ;-) ), ein Bild des alten Herren, sowie die aktuelle Gesprächsdauer.

Irgendwann endet das Gespräch, der Altenpfleger legt auf und der ältere Herr kann sich in Ruhe eine Zusammenfassung der Gesprächsfakten ansehen. Da bei der Videokonferenz ein Termin verabredet wurde, wird auch diese Info angezeigt und der erfolgreiche Kalendereintrag mit einem grünen Licht bekräftigt.
Szenenaufbau / -information
Die Erstellung der Inventarobjekte fing bereits kurz nach meiner Einstellung am IGD im Jahre 2008 an.
Alle in der Szene befindlichen Inventarobjekte wurden von mir mit 3ds max angefertigt und wir werden sie noch in einem weiteren Post wiedersehen. Als Vorlage für die Schrankwand, den Tisch und die Couchgarnitur diente mir der damals aktuelle Katalog eines bekannten schwedischen Einrichtungskonzerns.
Die Objekte bestehen aus über 200.000 Polygonen und sind durch den hohen Detailgrad auch für Nahaufnahmen geeignet.
 Als ich die Objekte angefangen habe zu modellieren, schien es mir, als hätte ich ewig Zeit zur Vollendung, da keine genauen Vorgaben getätigt wurden. Es wurden einfach "so viele Objekte wie möglich" gebraucht. Doch in der Branche sollte man sich auf so ein Gefühl nie verlassen, wie ich doch recht schnell merken sollte. Von jetzt auf gleich wurde mir Aufgetragen diese Storyboard-Szenen zu erstellen und plötzlich war die Ewigkeit sehr endlich. Ich hatte bis zu dem Augenblick zwar schon einige Objekte fertiggestellt, doch passten viele der Objekte thematisch nicht in diese Szene. Aus diesem Grund sieht man auch die doch recht leeren Regale in der Schrankwand. Eine wichtige Regel trat das erste Mal in mein berufliches Dasein: "Effizienz vor Perfektion". Jetzt hieß es schnell fertig werden, egal ob nun alle Details perfektioniert waren, oder nicht.
Als ich die Objekte angefangen habe zu modellieren, schien es mir, als hätte ich ewig Zeit zur Vollendung, da keine genauen Vorgaben getätigt wurden. Es wurden einfach "so viele Objekte wie möglich" gebraucht. Doch in der Branche sollte man sich auf so ein Gefühl nie verlassen, wie ich doch recht schnell merken sollte. Von jetzt auf gleich wurde mir Aufgetragen diese Storyboard-Szenen zu erstellen und plötzlich war die Ewigkeit sehr endlich. Ich hatte bis zu dem Augenblick zwar schon einige Objekte fertiggestellt, doch passten viele der Objekte thematisch nicht in diese Szene. Aus diesem Grund sieht man auch die doch recht leeren Regale in der Schrankwand. Eine wichtige Regel trat das erste Mal in mein berufliches Dasein: "Effizienz vor Perfektion". Jetzt hieß es schnell fertig werden, egal ob nun alle Details perfektioniert waren, oder nicht.
Eines der wichtigsten Objekte in der Szene, das Modell des alten Herren, stammt im Original nicht von mir. Da die Entscheidung Szenen mit einer älteren virtuellen Person zu erstellen, relativ kurzfristige gefasst wurde, entschieden wir uns fertige Modelle aus einer gewerblich vertriebenen Modellsammlung zu lizenzieren.
Dies sollte die Entwicklung des Strips beschleunigen. Da wir uns jedoch für eine recht günstige Modellvariante entschieden, war die Qualität nur suboptimal und ich musste noch viel Arbeit in die Optimierung investieren. Dadurch schrumpfte die erhoffte Zeitersparnis wieder stark zusammen.
 Die zwei größten Kritikpunkte waren:
Die zwei größten Kritikpunkte waren:
1. Das Mesh war wohl für Echtzeitanwendungen bestimmt und somit recht polygonarm, wodurch die Person etwas deplatziert in der Szene wirkte.
2. Das Rigging war schlecht umgesetzt worden - das Skelett passte nicht richtig zum Mesh. Zusammen mit dem (zu) einfachen Mesh, zeigte unser armer Alter beim Bewegen nicht nur Anzeichen von Gicht, sondern auch schwere Frakturen in den Händen, Armen und Beinen auf. Das war jedoch nicht unsere Absicht!
Es gab aber auch echte Vorzüge des gekauften Modells: Ich lernte nicht nur neue Kniffe beim ausbessern des Riggings, sondern hatte auch die Erleichterung keine Texturen für das Modell anfertigen zu müssen - diese waren, im Kontrast zum Modell, erstaunlich gut.
Die Komposition der Szene war dann der einfachste Teil. Mein Betreuer musste als Altenpfleger vor die Fotokamera und schließlich als Teil der Fernsehtextur herhalten. Die Objekte wurden platziert und es blieb sogar noch ein wenig Zeit dem alten Herren ein offenes Buch zu spendieren, anstelle ihm nur die geschlossenen Buchattrappen in die Hand zu drücken.
Für die Texturen kam eine Mischung aus selbst in Photoshop angefertigten und aus opensource Quellen stammenden Bilddateien zum Einsatz.
Die Szene wird ausschließlich von MR.Area Omni-Lights beleuchtet und mit MentalRay gerendert.
Damit wäre auch schon der erste Exkurs zu einer meiner Arbeiten am IGD Darmstadt beendet. Weitere werden folgen. Ich hoffe es gefällt euch. Falls ihr Kritik und / oder Anmerkungen habt, hinterlasst mir doch einfach einen Kommentar. ;)
Dazu habe ich freundlicherweise die Erlaubnis erhalten einen Teil meiner Arbeit hier auf meinem Blog zu veröffentlichen und ein wenig über den Entstehungsprozess zu berichten.
Nursing Service - Storyboard-Actionsequenz
Beginnen möchte ich die mehrteilige Präsentation mit einer in Bilderserie, welche für ein Projekt-Proposal ende des Jahres 2008 erstellt und genutzt wurde.
Es handelt sich bei dieser Bilderserie um ein Aktionssequenz über fünf Bilder, welche einen eingehenden Anruf eines Altenpflegers bei einem älteren Herren, über die im Haus verfügbaren Multimedia-Geräte und die intelligente Lichtsteuerung, sowie die Absprache eines Termins zeigt.
Speziell wird hier eine Videokonferenz über den Fernseher mit eingebauter Videokamera zwischen Altenpfleger und der zu betreuenden Person geführt.
Die Sequenz

Ein älterer Herr sitzt zu Hause auf dem Sofa und liest bei gedimmtem Licht und eingeschalteter Leseleuchte ein Buch.

Plötzlich schaltet sich der Fernseher ein und zeigt eine Nachricht an, welche einen Anruf vom Altenpfleger verkündet. Um die Aufmerksamkeit noch stärker auf sich zu lenken und die Art der aktuellen Situation zu verdeutlichen, wird zusätzlich ein blaues Licht hinter dem Fernseher aktiviert.

Der ältere Herr ist mit dem Anruf einverstanden und tätigt eine Annahme-Geste, indem er seine Hand mit der Handfläche nach oben hochhebt. Dies hat zur Folge, dass die Raumbeleuchtung verstärkt...

... und die Videokonferenz gestartet wird. Auf dem Fernseher sieht man den Altenpfleger (schönen Gruß an Felix! ;-) ), ein Bild des alten Herren, sowie die aktuelle Gesprächsdauer.

Irgendwann endet das Gespräch, der Altenpfleger legt auf und der ältere Herr kann sich in Ruhe eine Zusammenfassung der Gesprächsfakten ansehen. Da bei der Videokonferenz ein Termin verabredet wurde, wird auch diese Info angezeigt und der erfolgreiche Kalendereintrag mit einem grünen Licht bekräftigt.
Szenenaufbau / -information
Die Erstellung der Inventarobjekte fing bereits kurz nach meiner Einstellung am IGD im Jahre 2008 an.
Alle in der Szene befindlichen Inventarobjekte wurden von mir mit 3ds max angefertigt und wir werden sie noch in einem weiteren Post wiedersehen. Als Vorlage für die Schrankwand, den Tisch und die Couchgarnitur diente mir der damals aktuelle Katalog eines bekannten schwedischen Einrichtungskonzerns.
Die Objekte bestehen aus über 200.000 Polygonen und sind durch den hohen Detailgrad auch für Nahaufnahmen geeignet.
 Als ich die Objekte angefangen habe zu modellieren, schien es mir, als hätte ich ewig Zeit zur Vollendung, da keine genauen Vorgaben getätigt wurden. Es wurden einfach "so viele Objekte wie möglich" gebraucht. Doch in der Branche sollte man sich auf so ein Gefühl nie verlassen, wie ich doch recht schnell merken sollte. Von jetzt auf gleich wurde mir Aufgetragen diese Storyboard-Szenen zu erstellen und plötzlich war die Ewigkeit sehr endlich. Ich hatte bis zu dem Augenblick zwar schon einige Objekte fertiggestellt, doch passten viele der Objekte thematisch nicht in diese Szene. Aus diesem Grund sieht man auch die doch recht leeren Regale in der Schrankwand. Eine wichtige Regel trat das erste Mal in mein berufliches Dasein: "Effizienz vor Perfektion". Jetzt hieß es schnell fertig werden, egal ob nun alle Details perfektioniert waren, oder nicht.
Als ich die Objekte angefangen habe zu modellieren, schien es mir, als hätte ich ewig Zeit zur Vollendung, da keine genauen Vorgaben getätigt wurden. Es wurden einfach "so viele Objekte wie möglich" gebraucht. Doch in der Branche sollte man sich auf so ein Gefühl nie verlassen, wie ich doch recht schnell merken sollte. Von jetzt auf gleich wurde mir Aufgetragen diese Storyboard-Szenen zu erstellen und plötzlich war die Ewigkeit sehr endlich. Ich hatte bis zu dem Augenblick zwar schon einige Objekte fertiggestellt, doch passten viele der Objekte thematisch nicht in diese Szene. Aus diesem Grund sieht man auch die doch recht leeren Regale in der Schrankwand. Eine wichtige Regel trat das erste Mal in mein berufliches Dasein: "Effizienz vor Perfektion". Jetzt hieß es schnell fertig werden, egal ob nun alle Details perfektioniert waren, oder nicht.Eines der wichtigsten Objekte in der Szene, das Modell des alten Herren, stammt im Original nicht von mir. Da die Entscheidung Szenen mit einer älteren virtuellen Person zu erstellen, relativ kurzfristige gefasst wurde, entschieden wir uns fertige Modelle aus einer gewerblich vertriebenen Modellsammlung zu lizenzieren.
Dies sollte die Entwicklung des Strips beschleunigen. Da wir uns jedoch für eine recht günstige Modellvariante entschieden, war die Qualität nur suboptimal und ich musste noch viel Arbeit in die Optimierung investieren. Dadurch schrumpfte die erhoffte Zeitersparnis wieder stark zusammen.
 Die zwei größten Kritikpunkte waren:
Die zwei größten Kritikpunkte waren:1. Das Mesh war wohl für Echtzeitanwendungen bestimmt und somit recht polygonarm, wodurch die Person etwas deplatziert in der Szene wirkte.
2. Das Rigging war schlecht umgesetzt worden - das Skelett passte nicht richtig zum Mesh. Zusammen mit dem (zu) einfachen Mesh, zeigte unser armer Alter beim Bewegen nicht nur Anzeichen von Gicht, sondern auch schwere Frakturen in den Händen, Armen und Beinen auf. Das war jedoch nicht unsere Absicht!
Es gab aber auch echte Vorzüge des gekauften Modells: Ich lernte nicht nur neue Kniffe beim ausbessern des Riggings, sondern hatte auch die Erleichterung keine Texturen für das Modell anfertigen zu müssen - diese waren, im Kontrast zum Modell, erstaunlich gut.
Die Komposition der Szene war dann der einfachste Teil. Mein Betreuer musste als Altenpfleger vor die Fotokamera und schließlich als Teil der Fernsehtextur herhalten. Die Objekte wurden platziert und es blieb sogar noch ein wenig Zeit dem alten Herren ein offenes Buch zu spendieren, anstelle ihm nur die geschlossenen Buchattrappen in die Hand zu drücken.
Für die Texturen kam eine Mischung aus selbst in Photoshop angefertigten und aus opensource Quellen stammenden Bilddateien zum Einsatz.
Die Szene wird ausschließlich von MR.Area Omni-Lights beleuchtet und mit MentalRay gerendert.
Damit wäre auch schon der erste Exkurs zu einer meiner Arbeiten am IGD Darmstadt beendet. Weitere werden folgen. Ich hoffe es gefällt euch. Falls ihr Kritik und / oder Anmerkungen habt, hinterlasst mir doch einfach einen Kommentar. ;)
Freitag, 4. Februar 2011
Googles Blogger-App jetzt im Android-Market verfügbar!
Seit kurzem dürfen sich Android-User auch unterwegs per Smartphone auf bequeme Weise ihrem Blogger-Blog widmen.
Google hat jetzt die hauseigene Blogger-App über den Android-Market freigegeben. Wie sie sich im Alltag schlägt probiere ich gerade mit diesem Blogeintrag aus!
Die App ist sehr übersichtlich und einfach aufgebaut. Beim ersten Start wählt man sein Google-Konto aus und die App holt sich die damit assoziierten Blogger-Blogs.
Die App von oben links nach unten rechts:
- Blogger-Logo
- Stift-Symbol zum erstellen eines neuen Blogeintrags.
- Listenübersicht alles (mobiler!!!) Blogeinträge und -entwürfe
- Darunter ein Dropdown-Menü zur Auswahl der Blogs
- Ein Eingabefeld für die Überschrift des Posts
- Das Post-Eingabefeld an sich.
Jetzt beginnen die Goodies, welche hoffentlich mit weiteren Versionen reicher ausfallen.
Momentan haben wir:
- Mögleichkeit zur Aufnahme von Bildern über die Kamera
- Möglickeit zur Auswahl eines Galleriebildes
Dann folgt noch ein Label-Feld, sowie die Möglichkeit den eigenen Standort frei zu geben, an dem man den Blogeintrag erstellt hat. Grösstes Manko welches mir eben aufgefallen ist:
Man kann nur aus einer vorhandenen Liste aus Vorschlägen den Standort auswählen, aber diesen nicht direkt hier editieren bzw. Alternativen suchen. Hoffentlich wird das noch erweitert.
Letztendlich folgt noch ein Button zur Veröffentlichung, welchen ich gleich mal betätigen werde, ein Speichern-Button zum manuellen sichern eures Entwurfes und ein Lösch-Button.
Die App speichert euren Fortschritt auch automatisch, sobald die App bzw. die Editor-Activity den Fokus verliert - man z.B. in die Listenansicht wechselt, oder auf den Homescreen, etc.
Noch ist die App komplett auf Englisch, aber aufgrund der wenigen Bedienelemente auch für Leute ohne Englisch-Kenntnisse in meinen Augen leicht bedienbar.
Die App kann man im Android-Market über euer Smartphone, oder ganz neu, über die Android-Market-Website auf dem Computer direkt auf das Smartphone schicken lassen und ist auch komplett kostenlos - wie alle Apps direkt von Google.
Hier gehts zum Market:
http://market.android.com/details?id=com.google.android.apps.blogger
- Edit: URLs werden leider nicht automatisch in Links konvertiert... Ich versuche es mal mit HTML-Tags (leider habe ich in der App noch keine Text-Edit-Werkzeuge gefunden, somit sind zur Zeit nur ganz formatlose Texte ohne grossen Aufwand erstellbar)
- Edit #2: Auch HTML wird nicht erkannt, sondern direkt als Text ausgegeben... :-(
Abonnieren
Posts (Atom)