Meine Arbeit trägt den Titel „Visual-aided selection of
reactive elements in intelligent environments“ (Visuell gestützte Selektion
reaktiver Elemente in intelligenten Umgebungen) und behandelt die Problematiken
bei der Interaktion zwischen Menschen und Computern mittels
Gestensteuerung.
Die Problemstellung und die damit verbundene Aufgabenstellung wandelten sich während der Bearbeitungsphase. In der ursprünglichen Aufgabenstellung sollte ich untersuchen, welche Art von Rückmeldung der
Mensch benötigt, um in einer intelligenten Umgebung mit
reaktiven Elementen mittels Gesten zu interagieren.
Normalerweise ist das Verständnis einer Interaktion mit einem Computer folgende: Man hat ein Eingabegerät und ein Ausgabegerät – alles was man mit dem Eingabegerät anstellt hat eine mehr oder minder direkte Auswirkung auf das Ausgabegerät. Beim handelsüblichen Computer wäre das Eingabegerät z.B. die Maus, das Ausgabegerät der z.B. Monitor. Wähle ich nun ein Programmsymbol mittels der Maus aus, so sehe ich auf dem Bildschirm irgendeine optische Reaktion auf meine Tat - z.B. blinkt und springt das Symbol. Klicke ich auf das Symbol, passiert eine weitere Reaktion, welche ich auf dem Monitor angezeigt bekomme - z.B. ein Programm wird gestartet und angezeigt. In der heutigen Zeit verlagern sich Computersysteme jedoch immer mehr vom ursprünglich festen Arbeitsplatz, wie dem Schreibtisch, in alle Bereiche unserer Umgebung; sie werden Mobil wie z.B. durch das Smartphone oder ein Tablet-PC, oder integrieren sich sogar in Haushaltsgegenstände wie z.B. Kühlschränke, Fernseher oder gar Möbel. Während nun ein solches mobiles Gerät - beispielsweise ein Smartphone - weiterhin einen Bildschirm enthält und die Interaktion direkt über den Touchscreen erfolgt, muss dies nicht für einen Kühlschrank, oder ein Sofa gelten.
Normalerweise ist das Verständnis einer Interaktion mit einem Computer folgende: Man hat ein Eingabegerät und ein Ausgabegerät – alles was man mit dem Eingabegerät anstellt hat eine mehr oder minder direkte Auswirkung auf das Ausgabegerät. Beim handelsüblichen Computer wäre das Eingabegerät z.B. die Maus, das Ausgabegerät der z.B. Monitor. Wähle ich nun ein Programmsymbol mittels der Maus aus, so sehe ich auf dem Bildschirm irgendeine optische Reaktion auf meine Tat - z.B. blinkt und springt das Symbol. Klicke ich auf das Symbol, passiert eine weitere Reaktion, welche ich auf dem Monitor angezeigt bekomme - z.B. ein Programm wird gestartet und angezeigt. In der heutigen Zeit verlagern sich Computersysteme jedoch immer mehr vom ursprünglich festen Arbeitsplatz, wie dem Schreibtisch, in alle Bereiche unserer Umgebung; sie werden Mobil wie z.B. durch das Smartphone oder ein Tablet-PC, oder integrieren sich sogar in Haushaltsgegenstände wie z.B. Kühlschränke, Fernseher oder gar Möbel. Während nun ein solches mobiles Gerät - beispielsweise ein Smartphone - weiterhin einen Bildschirm enthält und die Interaktion direkt über den Touchscreen erfolgt, muss dies nicht für einen Kühlschrank, oder ein Sofa gelten.
 |
| Auf der Cyberworld 2012 vorgestelltes Paper |
Noch gravierender wird es, wenn die einzelnen Geräte miteinander kommunizieren und Daten untereinander austauschen. So ist es bereits heute im Living Lab - einer intelligenten Wohnumgebung die als Test- und Demobereich für Ambient Intelligence Forschung am Fraunhofer IGD dient - möglich durch das Einnehmen bestimmter Sitzpositionen auf dem Sofa die Lichtstimmung im Raum zu verändern. Dieses Beispiel einer indirekten Steuerung zeigt, dass es nicht immer offensichtlich sein muss, welche Reaktion auf eine Aktion folgt. Eine nicht instruierte Person kann die Möglichkeit der Veränderung der Lichtstimmung erst durch das erstmalige Hinsetzen bemerken. Welche Lichtstimmungen möglich sind, muss sie durchs Probieren herausfinden.
Um dem zumindest im Bereich der Gestensteuerung entgegenzuwirken sollte ich nicht nur das Problemfeld
näher betrachten, sondern meine Erkenntnisse zur Verbesserung der
Situation auch durch eine funktionale Umsetzung demonstrieren.
Dank der Markteinführung von Microsofts Kinect und der aktiven Gemeinschaft unabhängiger Entwickler, stand eine sehr preisgünstige und für meine Zwecke ideale Technologie zum Erkennen und Verarbeiten von Gesten bereit. Die Tiefenkamera von Microsoft erkennt die Silhouetten davorstehender Personen und berechnet aus diesen ein vereinfachtes Skelettmodell mit allen benötigten dreidimensionalen Werten. So kann man z.B. die Zeigerichtung im Raum erkennen und für die Interaktion nutzen.
Dank der Markteinführung von Microsofts Kinect und der aktiven Gemeinschaft unabhängiger Entwickler, stand eine sehr preisgünstige und für meine Zwecke ideale Technologie zum Erkennen und Verarbeiten von Gesten bereit. Die Tiefenkamera von Microsoft erkennt die Silhouetten davorstehender Personen und berechnet aus diesen ein vereinfachtes Skelettmodell mit allen benötigten dreidimensionalen Werten. So kann man z.B. die Zeigerichtung im Raum erkennen und für die Interaktion nutzen.

 Die Art der Eingabe abseits von Maus und Tastatur war also
vorhanden, doch wie sollte die Ausgabe aussehen, so dass kein stationärer, oder
mobiler Bildschirm benötigt wurde? Die Nutzung eines solchen stationären Ausgabegerätes hätte zwei gravierende Nachteile, die ich in meiner Arbeit aufzeigen und vermeiden wollte. Zum Einen müsste ein mobiler
Bildschirm immer in irgend einer Art und Weise mitgeführt werden, was wiederum der „Unaufdringlichkeit“
einer intelligenten Umgebung entgegenwirken würde, zum Anderen könnte ein stationärer
Bildschirm, wie z.B. der Fernseher im Wohnzimmer, nicht überall für die
benötigte Rückmeldung genutzt werden, weil er z.B. nicht im Blickfeld steht. Auch andere Ausgabevarianten, wie akustische Meldungen, oder Vibrationsmotoren
in der Kleidung - um nur zwei zu nennen – schieden aus. Diese würden entweder
aufdringlich in den Wahrnehmungsbereich einer zweiten Person, welche mit der Interaktion
nichts zu tun hat, dringen, oder
müssten wiederum ständig mitgeführt werden.
Die Art der Eingabe abseits von Maus und Tastatur war also
vorhanden, doch wie sollte die Ausgabe aussehen, so dass kein stationärer, oder
mobiler Bildschirm benötigt wurde? Die Nutzung eines solchen stationären Ausgabegerätes hätte zwei gravierende Nachteile, die ich in meiner Arbeit aufzeigen und vermeiden wollte. Zum Einen müsste ein mobiler
Bildschirm immer in irgend einer Art und Weise mitgeführt werden, was wiederum der „Unaufdringlichkeit“
einer intelligenten Umgebung entgegenwirken würde, zum Anderen könnte ein stationärer
Bildschirm, wie z.B. der Fernseher im Wohnzimmer, nicht überall für die
benötigte Rückmeldung genutzt werden, weil er z.B. nicht im Blickfeld steht. Auch andere Ausgabevarianten, wie akustische Meldungen, oder Vibrationsmotoren
in der Kleidung - um nur zwei zu nennen – schieden aus. Diese würden entweder
aufdringlich in den Wahrnehmungsbereich einer zweiten Person, welche mit der Interaktion
nichts zu tun hat, dringen, oder
müssten wiederum ständig mitgeführt werden.
Das Rückmeldesystem sollte somit vor Ort aber nicht
stationär, mobil aber nicht am Körper des Benutzers und überall im Raum
verfügbar, aber nicht aufdringlich und störend sein. Die Lösung, welche mir am
geeignetsten erschien, war also eine optische Darstellung der Ausgabe mittels
Projektion. Im Rahmen der Bachelorarbeit baute ich einen
kleinen Laserprojektor, der mittels Modellbau-Motoren ausgerichtet und durch
einen Arduino Mikrocontroller und einem umfangreichen Softwarepaket gesteuert
wurde. Das projizierte Licht lieferte eine kleine LED Laserdiode.
Als Resultat entstand das Environmental Aware Gesture Leading Equipment (E.A.G.L.E.) System.

Den Projektionsroboter taufte ich E.A.G.L.E. Eye.
Die Implementierung des gesamten Systems erforderte einen erheblichen Teil meiner dreimonatigen Thesis-Zeit, viele graue Haare, noch mehr schlaflose Nächte und einen nicht unbedeutenden Anteil meines Nervenkostüms, doch das Resultat sollte sich auszahlen.
Bezüglich der detaillierten Implementierung der Hardware und Software werde ich mich an dieser Stelle kurz fassen.
Einige interessante Aspekte der Umsetzung bieten aber Stoff für weitere Artikel auf meinem Blog und sollen dann auch den dafür nötigen Rahmen erhalten.
Bezüglich der detaillierten Implementierung der Hardware und Software werde ich mich an dieser Stelle kurz fassen.
Einige interessante Aspekte der Umsetzung bieten aber Stoff für weitere Artikel auf meinem Blog und sollen dann auch den dafür nötigen Rahmen erhalten.
Um ein Verständnis der technischen Umsetzung zu erhalten kann man die Funktionsweise des E.A.G.L.E. Systems in folgenden Punkten beschreiben:
- Die Kinect erkennt den Benutzer und erstellt eine virtuelle Skelettdarstellung
- Das Skelett wird dazu benutzt die Zeige und Auswahlgesten zu erkennen.
- Diese Gesten werden mit einer virtuellen Repräsentation des Raums und seiner Geräte in Relation gesetzt.
- Die erkannte Zeigegeste in diesem virtuellen Raum bzw. die Auswahl eines Gerätes in diesem wird als Befehlssatz an das E.A.G.L.E. Eye gesendet.
- Das E.A.G.L.E. Eye richtet den Laserpunkt auf die Position im reellen Raum aus.

 |
| E.A.G.L.E. Eye |
- Dauerhaftes Leuchten beim Zeigen in den Raum
- Blinken beim Zeigen auf ein reaktives Gerät
- Schnelles Blinken bei erfolgter Auswahl des Gerätes [2]
Wie ich oben bereits erwähnt habe, war die ursprüngliche
Idee der Bachelor Thesis die Herausarbeitung verschiedener Feedback-Varianten.
Angedacht war zu untersuchen ob
komplexere Menüstrukturen nötig sind und in wieweit diese die gestenbasierte Interaktion mit einem Gerät beeinflussen. Des Weiteren sollte herausgefunden werden, wie komplex eine solche Menüstruktur mindestens sein muss, oder höchstens sein darf, damit sie
trotz Gestensteuerung noch gut bedienbar bleibt.
Der Schwerpunkt änderte sich jedoch immer mehr, je weiter
die Entwicklung am E.A.G.L.E. System voranschritt. Gleich nach den ersten
Testläufen durch meine beiden Betreuer Andreas Braun, Alexander Marinc und mir selbst stellte sich eine ganz andere Frage:
Mit welchem Teil meines Arms zeige ich wohin in den Raum?
Diese Frage mag verwundern, zeigen wir Menschen doch Tag
ein, Tag aus irgendwo hin und irgendwo drauf und werden zumeist ohne weiteres von unseren Mitmenschen verstanden - falls nicht, erklären wir unsere Intention auf einem anderen Wege wie z.B. verbal.
So bedeutungslos die Frage somit auch klingen mag, so tiefgehend beeinflusste sie die Testläufe: Drei Personen testeten den E.A.G.L.E Prototypen, drei Personen waren komplett unterschiedlicher Meinungen darüber mit welchen Teilen ihres Oberkörpers sie auf welchen Punkt im Raum zeigten.
Diese Diskrepanz wird dadurch ausgelöst, dass auf der anderen Seite der Interaktionskette kein Mensch sondern ein Computersystem sitzt. Bereits die wichtigste Komponente dieser Kette macht einer intuitiven Interaktion einen Strich durch die Rechnung: Die Kinect! Dieses für die Thesis interessante, weil kostengünstige und gut programmierbare Gerät liefert ein sehr einfaches Skeletmodel aus den Bilddaten, über welches man die Zeigegesten interpretieren muss. Zur Anschauung dient folgende Abbildung und die drei möglichen Wege eine einfache Zeigerichtung zu bestimmen:
So bedeutungslos die Frage somit auch klingen mag, so tiefgehend beeinflusste sie die Testläufe: Drei Personen testeten den E.A.G.L.E Prototypen, drei Personen waren komplett unterschiedlicher Meinungen darüber mit welchen Teilen ihres Oberkörpers sie auf welchen Punkt im Raum zeigten.
Diese Diskrepanz wird dadurch ausgelöst, dass auf der anderen Seite der Interaktionskette kein Mensch sondern ein Computersystem sitzt. Bereits die wichtigste Komponente dieser Kette macht einer intuitiven Interaktion einen Strich durch die Rechnung: Die Kinect! Dieses für die Thesis interessante, weil kostengünstige und gut programmierbare Gerät liefert ein sehr einfaches Skeletmodel aus den Bilddaten, über welches man die Zeigegesten interpretieren muss. Zur Anschauung dient folgende Abbildung und die drei möglichen Wege eine einfache Zeigerichtung zu bestimmen:

- Als Linie zwischen Kopf und Handgelenk
- Als Linie zwischen Schultergelenk und Handgelenk
- Als Linie zwischen Ellbogen und Handgelenk
Und ausgerechnet die dem Menschen am meisten bevorzugte Variante, das Zeigen über die Gelenke des Zeigefinders, kann nicht genutzt werden. Zur Darstellung der Finger ist die Kinect (der ersten Generation) nicht technisch in der Lage - es wäre unter bestimmten Vorraussetzungen möglich, aber für mein Aufgabenfeld nicht umsetzbar.
Doch auch wenn die Technik diese Beschränkung nicht inne hätte, wäre die Problematik längst nicht vom Tisch. So hat sich schnell herausgestellt, dass der eine Proband immer über die Augen zur Spitze seines Zeigefingers zeigt, während ein anderer Proband gerne den Unterarm als Verlängerung seines "Zeigegerätes" benutzt. Viel gravierender als diese benutzerspezifische Vorliebe beim Zeigen ist der Unterschied zwischen der gedachten und der vom System erkannten Zeigerichtung und dem daraus resultierenden Zeigeziel. Während der Mensch der Meinung ist seinen Körper und seine Hand-Augen-Koordination perfekt zu beherrschen, entlarvt das Computersystem jedes Zittern und jeden Drift - z.B. durch Ermüdung der Muskeln. Diese Veränderungen mögen für den Menschen unmerklich groß sein, wirken sich aber numerisch bereits so gravierend aus, dass bereits auf wenigen Metern ein Versatz von mehreren Dezimetern entstehen kann. Anstelle somit auf den Fernseher zu zeigen, zeigt man auf die Blumenvase daneben und wundert sich, wieso der Fernseher nicht reagiert. Die technische Umsetzung der Kinect steuert zu dieser Variant sicherlich ihren Teil bei, doch auch eine präzisere Sensortechnik nicht zu 100% mit der Intention des Benutzers übereinstimmen.
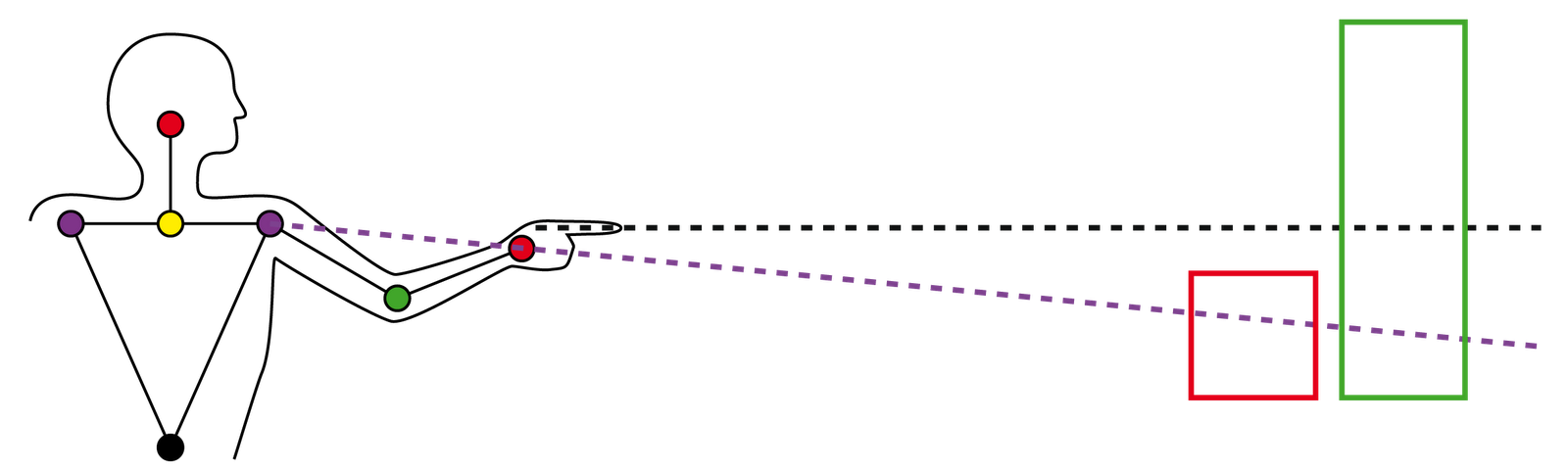 |
| Unterschied zwischen gedachter und erkannter Zeigerichtung. |
 |
| Bereits geringe Schwankungen führen zu erheblichem Richtungsversatz. |
Nutzt man nun ein klassisches System, wie den oben genannten
Desktop PC mit der Maus als Zeigegerät, so hat man mehrere begünstigende
Faktoren sein Ziel auch zu erreichen. Die Maus liegt recht stabil auf der
Unterlage. Lässt man sie los, so bleibt sie zumeist auch dort liegen. Bewegt man die
Maus, so bewegt man zwar faktisch seine Hand, folgt aber dem Mauszeiger auf dem
Bildschirm. Ohne diesen Zeiger und ohne eine stabile Ruheposition wäre es auch hier nicht möglich präzise mit dem PC zu interagieren.
Wenn aber der Mensch am PC in der Lage ist einem Mauszeiger
zu folgen, der räumlich so drastisch getrennt vom physikalischen Zeigegerät
ist, wieso sollte das nicht auch im reellen Raum mittels Zeigegesten funktionieren? Muss der Mensch
nicht einfach nur verstehen was der PC erkennt und interpretiert, um sich an diesen anzupassen?
Ist die Adressierung der Anpassung von Seiten des Menschen nicht deutlich einfacher, als wenn man
komplexe Algorithmen schreibt, welche man an den Menschen anpassen muss?
Diesen Fragen in Kombination mit der banal anmutenden Frage „Wo zeige ich
eigentlich hin?“ widmete ich von diesem Zeitpunkt an meine Bachelorarbeit. Nun
war es nicht mehr wichtig verschiedene Darstellungen zu erproben und zu schauen
wie komplex diese werden müssen, sondern einfach darum überhaut einen anständig
funktionierenden Navigations- und Auswahlprozess im intelligenten Raum mittels
Zeigegesten zu ermöglichen.
Das E.A.G.L.E. System wurde dahingehend erweitert, dass
genau dieser Prozess der Navigation und der Geräteauswahl anständig und in
annähernder Echtzeit funktioniert.
Meine Hypothese: Der Mensch ist ohne ein angemessenes
Rückmeldesystem nicht in der Lage eine durchgehend erfolgreiche Auswahlaktion
im Raum mittels Gesten durchzuführen, auch wenn man ihn detailliert über die
Berechnungsweise seiner Zeigegeste instruiert. Die Aussicht auf Erfolg dieses
Prozesses lässt sich durch ein geeignetes Rückmeldesystem signifikant
verbessern. Dazu ist es im letzteren Fall nicht einmal mehr nötig das System
durch komplexere Algorithmen intelligenter zu gestalten.
Zur Evaluation lud ich zwanzig Testkandidaten ein, welche
einen festgelegten Parcours bestehend aus acht Zielen verschiedener Größe,
Orientierung und Position im Raum mit einer Zeigegeste ansteuern und durch zwei
Sekunden langes Halten dieser Zeigegeste auswählen sollten. Zehn dieser Personen
mussten den Parcours erst ohne, dann mit der Unterstützung des Laserprojektors
durchführen, die anderen zehn Personen genau in umgekehrter Reihenfolge.
Neben dem Nachweis der Hypothese erhoffte ich mir zusätzlich,
dass die Nutzung des E.A.G.L.E. Systems einen gewissen Lerneffekt für den
Durchlauf ohne das System auf die Kandidaten haben würde.
 Die Hypothese konnte ich mit absoluter Zufriedenheit
beweisen. Alle Personen waren mit der Unterstützung des Lasers zu 100% in der
Lage die Zielscheiben anzuvisieren und auszuwählen. Auch wenn es manchmal nicht
auf den ersten Fingerzeig geklappt hat, so wussten die Kandidaten um ihren
Fehler und konnten diesen korrigieren. Ohne die unterstützende Projektion waren
erfolgreiche Auswahlaktionen hingegen ein Akt des Zufalls. Sogar die großen
Ziele mit 3060 Quadratzentimetern - die Größe eines DinA3 Blattes - wurden nur selten erfolgreich ausgewählt.
Die Hypothese konnte ich mit absoluter Zufriedenheit
beweisen. Alle Personen waren mit der Unterstützung des Lasers zu 100% in der
Lage die Zielscheiben anzuvisieren und auszuwählen. Auch wenn es manchmal nicht
auf den ersten Fingerzeig geklappt hat, so wussten die Kandidaten um ihren
Fehler und konnten diesen korrigieren. Ohne die unterstützende Projektion waren
erfolgreiche Auswahlaktionen hingegen ein Akt des Zufalls. Sogar die großen
Ziele mit 3060 Quadratzentimetern - die Größe eines DinA3 Blattes - wurden nur selten erfolgreich ausgewählt.
So signifikant wie dieses Ergebnis ausfiel, so wenig konnte
ich über einen Lerneffekt herausfinden. Die festgestellten Unterschiede waren
nicht aussagekräftig genug. Ein Fall für weitere Untersuchungsanstrengungen?!
Nichtsdestotrotz war ich sehr zufrieden mit dem Ausgang der
Evaluation. Die Bachelorarbeit
gefiel anscheinend ebenso meinem betreuenden Professor Arian Kuijper, sowie meinen beiden
Betreuern Andreas Braun und Alexander Marinc: Die Thesis wurde mit einer glatten 1.0 bewertet.
Wer sich detaillierter für meine Bachelor Thesis oder derer Präsentation interessiert, der kann sie sich unter folgendem Link herunterladen und
durchlesen.
Als positiver Nebeneffekt der erbrachten wissenschaftlichen
Erkenntnisse wurde meine Bachelorarbeit in einem Paper auf der
diesjährigen Cyberworld veröffentlicht und präsentiert.
Des Weiteren möchte ich mich bei meinem Kumpel (und Chef) Felix Kamieth bedanken, der mich während der Abschlussarbeit nur ganz gering mit Arbeit zugeschüttet und moralisch oft unterstützt hat.
[1] Diese
Verbreitung wird als allgegenwärtige (ubiquitous) und verschwindende (vanishing) bzw. unaufdringliche (unobtrusive) Computerisierung
bezeichnet. Ein Raum, in welchem die verschiedensten Geräte nicht nur für sich
computergestützt arbeiten, sondern auch miteinander kommunizieren und Daten
austauschen, um irgend eine komplexere Funktionalität auszuführen (z.B. eine
Reaktion auf das Wohlbefinden eines Bewohners), heißt intelligenter Wohnraum (intelligent environment).
[2] Ein Gerät wird ausgewählt, wenn der Benutzer durchgehend mindestens zwei Sekunden lang auf dieses gezeigt hat.
[2] Ein Gerät wird ausgewählt, wenn der Benutzer durchgehend mindestens zwei Sekunden lang auf dieses gezeigt hat.